Three-day Thinking in Go (Day 1)
最近在公司内部参加了一个go programming的培训,一共三天,这个系列算作是我的个人笔记。即回顾所学的知识,又在整理的时候做了更多的查阅和阅读。当然这三天不能期待太多,都是非常基础的东西,所以适合有编程经验但是并不熟悉Go的读者。 希望日后时间从这个三天大纲式的笔记做一些延伸。
安装 (Mac)
建议是从 Homebrew 开始
安装 Homebrew
1ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
安装 Go
1brew install go
设置环境变量
查看Go的版本
go version
查看GO的当前环境变量
go env
确保 GO111MODULE=on 这样我们可以使用 go mod
设置 Workspace
在你的 shell (比如 .zshrc) 中设置
1export GOPATH=$HOME/go # go 会把这个当作是workspace
2export PATH="$GOPATH/bin:$PATH"
3export GO111MODULE=on # 如果你的go version是 1.11/1.12 你需要这个
设置完了记得 source一下 让其生效。
1source ~/.zshrc
Hello World 测试
mkdir -p ~/threedaygo/hello
cd ~/threedaygo/hello
go mod init github.com/threedaygo/hello
go mod 应该现在是go开发中 de facto 的依赖管理
创建一个 main.go
内容为
1package main
2
3import "fmt"
4
5func main() {
6 fmt.Println("Hello, let's do go in three days!")
7}
跑一下,确保可以看到输出
go run main.go
1go build main.go # build 一个bianry在当前folder
2./main
1go install main.go
2which main # 应该在你的go path 的bin folder 下
3main # 应该会执行
安装 golint
go get -u golang.org/x/lint/golint
在你的 main.go 里加入
1func hello_word() {}
跑 linter
1golint main.go
2# 应该会有: 不应该用undersocre来命名的警告
类型
原始类型
- string
- bool
- int, int[8,16,32,64], int 和 int32等 不是一个type
- uint, uint[8,16,32,64], 同理 uint 和 uint32等 也不是一个type
- int/uint的大小其实根据CPU决定的
- float32 flot64
- complex64 complex128
- byte (uint8) 可代表了一个ASCII字符
- rune (int32) 可代表一个UTF-8字符
1// 用var声明变量,变量会被初始化zero value
2// type在变量名后
3// 变量名用的驼峰
4var a int
5var str string // string的空值是“”
6
7// 用:= 简洁声明赋值
8a := 10
9
10// 声明并赋值
11var b int8 = 10
12var d = 10.2 // compiler infer
13fmt.Printf("%T\n", d) // float64
14
15// var block 声明多个
16var (
17 a1 int
18 str1 string
19 b1 float64
20)
21
22// 用back tick声明多行string
23a := `大家
24好
25`
阅读资料 变量的命名
string
string在go中作为基本类型, 是一个双字的结构
这里的字,通常指的是字长单位,即CPU做处理的自然数据单位,通常CPU里的数据传输是一个字长,寄存器的大小也是一个字长。比如目前主流的CPU字长应该是64bit
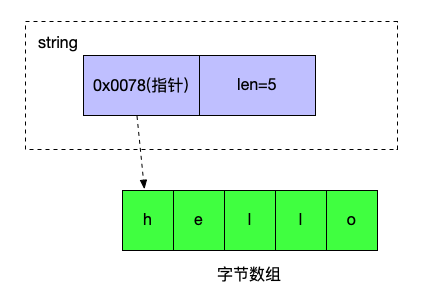
由于string使用一个数组来做数据存储,所以string是immutable的 string支持UTF8,所以这个数据array的单位应该是rune
常量 const
- 编译时即有值
- 有两种 typed 和 untyped
- 如果是untyped则会用256bits最高精度来装载
- 如果是typed则会用对应的type
- typed的常量可以bei
1const (
2 pi = 3.14 //untyped, float kind
3 double = 2 //untyped, int kind
4 piT float64 = pi // => 3.14 float64
5 doubleT int32 = double // => 2, int32
6 a // 沿用前面的值和type => 2, int32
7 b = 1 // => 1, int
8)
9
10
11func main() {
12 var (
13 a1 float32 = 2.0
14 a2 int = 10
15 )
16 fmt.Println("R1:", a1*pi) // float32变量和一个untyped float kind的常量数字相乘,ok
17 fmt.Println("R2:", a2*pi) // int变量和一个untyped float kind常量数字相乘,报错
18 fmt.Println("R3:", a2*double) // int变量和一个untyped int kind常量数字相乘,ok
19 fmt.Println("R4:", a2*doubleT) // int变量和一个float64 type常量相乘,报错
20}
iota
- 一个自增的赋值器
- 自增开始于下一个行
- 可以用 _ 来跳过
- Const block 会重设 iota
1 // 类型定义 (注意区分类型别名)
2 type Status int
3
4 const (
5 CREATED Status = iota + 1 // => 0 + 1
6 RUNING // => 1 + 1
7 STOPPED // => 2 + 1
8 _ // => 3 + 1
9 _ // => 4 + 1
10 ERROR // => 5 + 1
11 )
12
13 // const block 会重设iota
14 const (
15 Monday int = iota // 0
16 Tuesday // 1
17 Wednesday // 2
18 )
阅读资料 Rob Pike 在Go Blog 写了一些为何要设计成这样,感兴趣的应该读一读。
归纳一下的话就是
- numeric type 不能混用在运算中,因为这个是很多bug的来源
- 但是constant则没有这么严格,constant 不像是变量,更像是一个数字
类型提升 (type promotion)
- 没有自动type conversion,变量的话需要手动convert
- untyped constant 如果匹配的话,会自动提升类型
- 可以用 type定义自己的type
- 区分 type 定义和 type别名(alias)
结构体
从C继承过来的
- 关键字是 type 和 struct
- 可以做 type compose
- 用点来访问结构体成员
- struct也是初始化为0值
用 %#v 来打印struct
指针
指针也是从C集成过来
- 指针初始化是
new(T) *T应该对等c的malloc - 用
*dereference - 用
&取地址 - 指针的size取决于cpu
- 打印指针可以用
%p
1 a := 10
2 fmt.Printf("a: %-10T %p:%v\n", a, &a, a)
3
4 b := &a
5 fmt.Printf("b: %-10T %p:%p:%v\n", b, &b, b, *b)
6
7 var c *int
8 c = &a
9 fmt.Printf("c: %-10T %p:%p:%v\n", c, &c, c, *c)
10
11 var d = new(int)
12 *d = a
13 fmt.Printf("d: %-10T %p:%p:%v\n", d, &d, d, *d)
函数
- 函数也是一个类型
- 函数输入可以是多个变量,返回也可以是多个变量
- 函数命名一般用驼峰
- 通过首字母是否大小,决定函数是否可以包外使用
- 用
_省略不需要return - named return
- func可以被赋给一个变量
- clean code, 注意变量的和return变量的数目
- func call 会有stack frame
- 匿名函数
1// 函数可以做函数的输入变量
2pow := func(i int) int {
3 return i*i
4}
5fmt.Println(pow(100))
6
7// 匿名函数
8say := func(i int) func() string {
9 return func() string {
10 return fmt.Sprintf("this is a %d", i)
11 }
12}
13
14// func 有type
15type multiplier func(i int) int
控制语句
这里和其他的编程语言并没有很多不同
- 循环只有一个关键字 for
- for range
- defer
- goto
- 用
{}来定义scope - switch 的case 默认会break
- switch break( to branch)
- switch fallthrough/default
- panic
- recover
集合
数组
- 数组是一片连续分配的内存
- 数组是mutable
- 但是静态的,不能增长或者缩小
- typed,element必须是声明的type
- zero based index
- 初始化为0值
- cap
- len
- 对于数组, len==cap
- 数组是静态的, 大小在编译的时候是已知的,所以分配在栈上
1// 声明
2var a [5]int
3var b [2]bool
4
5// 赋值声明
6c := [3]float32{1,2,3}
7
8e := [3]float64{0: 1.1, 2:2.2}
9fmt.Printf("e = %#v\n", e) // => e = [3]float64{1.1, 0, 2.2}
10
11d := [...]float64{0: 1.1, 3:2.2}
12fmt.Printf("d = %#v\n", d) // => d = [4]float64{1.1, 0, 0, 2.2}
13
14// 可以对一数组切片
15fmt.Printf("d = %#v\n", d[1:3])
16fmt.Printf("d = %#v\n", d[1:])
17fmt.Printf("d = %#v\n", d[:2])
18fmt.Printf("d = %#v\n", d[:])
19
20// 循环访问数组
21for i :=0 ; i < len(d); i++ {
22 fmt.Printf("d[%d] %p:%s\n", i, &d[i], d[i])
23}
24
25for i, v := range d {
26 fmt.Printf("d[%d] %p:%s\n", i, &v, v)
27}
28
29// 多维数组
30e := [3][3]int{ {1, 1, 1}, {2, 2, 2}, {3, 3, 3} }
31for i := 0; i < len(e); i++ {
32 for j := 0; j < len(e[i]); j++ {
33 fmt.Printf("% d ", e[i][j])
34 }
35 fmt.Println()
36}
切片
- 利用数组来提供数据
- 自身是一个引用类型
- 可以增长
- 声明和array数组,但是
[]中没有长度 - len,cap,append
- 通过 make 来创建
- 是一个3字结构 (指向数组的指针,切片的长度,切片的容量)
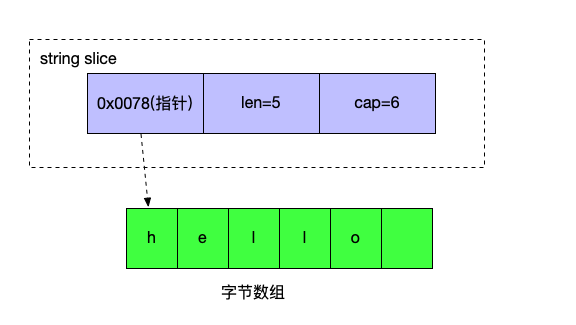
切片如何扩容?
切片相当于一个小的struct,指向切片的第一个元素
这里也有一个增长因子,当元素小于1024,每次需要扩容的时候都是翻倍,超过之后则是1.25。 如果增长之后,超过了原有数组的容量,go会开辟新的内存,把值拷贝过来,然后切片指向新的位置。
1package main
2
3import (
4 "fmt"
5)
6
7func main() {
8 a := [3]int{1, 2, 3}
9 b := a[2:]
10 c := a[2:]
11 for i := 1; i < 16; i++ {
12 fmt.Printf("b %T, %p, %p, %#v\n", b, b, &b, b)
13 b = append(b, i)
14 }
15 c[0] = 4
16 fmt.Printf("c %T, %p, %p, %#v\n", c, c, &c, c)
17 fmt.Printf("a %T, %p, %#v\n", a, &a, a)
18 fmt.Printf("b %T, %p, %p, %#v\n", b, b, &b, b)
19}
20
21
22// b []int, 0xc000014030, 0xc00000c0a0, []int{3}
23// b []int, 0xc00002c060, 0xc00000c0a0, []int{3, 1}
24// b []int, 0xc000014060, 0xc00000c0a0, []int{3, 1, 2}
25// b []int, 0xc000014060, 0xc00000c0a0, []int{3, 1, 2, 3}
26// b []int, 0xc00007c040, 0xc00000c0a0, []int{3, 1, 2, 3, 4}
27// b []int, 0xc00007c040, 0xc00000c0a0, []int{3, 1, 2, 3, 4, 5}
28// b []int, 0xc00007c040, 0xc00000c0a0, []int{3, 1, 2, 3, 4, 5, 6}
29// b []int, 0xc00007c040, 0xc00000c0a0, []int{3, 1, 2, 3, 4, 5, 6, 7}
30// b []int, 0xc000078100, 0xc00000c0a0, []int{3, 1, 2, 3, 4, 5, 6, 7, 8}
31// b []int, 0xc000078100, 0xc00000c0a0, []int{3, 1, 2, 3, 4, 5, 6, 7, 8, 9}
32// b []int, 0xc000078100, 0xc00000c0a0, []int{3, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
33// b []int, 0xc000078100, 0xc00000c0a0, []int{3, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11}
34// b []int, 0xc000078100, 0xc00000c0a0, []int{3, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12}
35// b []int, 0xc000078100, 0xc00000c0a0, []int{3, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13}
36// b []int, 0xc000078100, 0xc00000c0a0, []int{3, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14}
37// c []int, 0xc000014030, 0xc00000c0c0, []int{4}
38// a [3]int, 0xc000014020, [3]int{1, 2, 4}
39// b []int, 0xc000078100, 0xc00000c0a0, []int{3, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15}
这个结果怎么理解呢?一开始的slice大小为0 当我们开始append的时候,扩容就开始了,所以创建了一个新的backing struct,这里可以看出这里的扩容大概是2倍每次。 因在扩容的时候发生了拷贝,所以slice b下面已经不在是a数组做backing。而slice c还是,所以修改c的数据就体现在a, 但是b丝毫不受影响
图
- key-value
- 通过对key的hash决定value的位置
- key的类型,只要是comparable的即可(==)
- 所以,map,slice func 不能成为map的key
- 不是concurrency safe的
- 读取是unorder的
1m1 := map[string]int{}
2m2 := make(map[string]int)
3m3 := make(map[int]bool, 10)
4m4 := map[string]int{"a": 1, "b": 2, "c": 3}
5
6fmt.Printf("m1 = %#v\n", m1)
7fmt.Printf("m2 = %#v\n", m2)
8fmt.Printf("m3 = %#v\n", m3)
9fmt.Printf("m4 = %#v\n", m4)
10
11
12// 写
13m1["a"] = 1
14m1["b"] = 2
15
16// 读
17if v, ok := m1["c"]; ok {
18 fmt.Println(v, ok)
19} else {
20 fmt.Println("Not found!")
21}
22
23// 更新
24if v, ok := m["c"]; ok {
25 m["c"] = v + 1
26}
27
28// 删除
29delete(m, "b")
30
31// Map的元素是没办法addressable的
32type worker struct {
33 firstName, lastName string
34}
35
36m := map[string]worker{
37 "a": {
38 firstName: "b",
39 lastName: "c",
40 },
41}
42
43// 以下操作会报错
44m["a"].firstName = "d" // => cannot assign to struct field m["a"].firstName in map
45
46// 解决方法1 替换这个value
47e := m["a"]
48e.firstName = "d"
49m["a"] = e
50
51// 解决办法2 是放struct的指针到map中
52m := map[string]*worker{
53 "a": &worker{
54 firstName: "b",
55 lastName: "c",
56 },
57}
58m["a"].firstName = "d"
59fmt.Println(m["a"].firstName)
GO入门系列
