[SOSP'07] Dynamo: Amazon's Highly Available Key-value Store
@article{decandia2007dynamo,
title={Dynamo: amazon's highly available key-value store},
author={DeCandia, Giuseppe and Hastorun, Deniz and Jampani, Madan and Kakulapati, Gunavardhan and Lakshman, Avinash and Pilchin, Alex and Sivasubramanian, Swaminathan and Vosshall, Peter and Vogels, Werner},
journal={ACM SIGOPS operating systems review},
volume={41},
number={6},
pages={205--220},
year={2007},
publisher={ACM New York, NY, USA}
}
This paper presents the design of a key-value store to achieve Realibality/Availability at massive scale at Amazon. And it has huge impact on Cassandar and lots of nosql databases that have been created during the decade.
Its importance toward NoSQL revolution is unquestionable.
To achieve this level of availability, Dynamo sacrifices consistency under certain failure scenarios.
Introdcution
One of the lessons our organization has learned from operating Amazon’s platform is that the reliability and scalability of a system is dependent on how its application state is managed.
The client should be able to read and write to the data store no matter what happens:
- disks are failing
- network routes are flapping (failures shouldn’t affect availability)
- data centers are being destroyed by tornados (work across multipl data centers)
- need scale as well.
Why Dynamo is designed as key value store?
Many services on Amazon’s platform that only need primary-key access to a data store.
Technique used for scalability and availability
- consistent hashing
- object versioning
- quorum for consistency
- gossip based dsitributed failure detection and membership protocol
Background
System Assumption and Requirements
Query Model
- read/write to a data that can be ideitified by a key.
- state is stored in data is a binary object.
- no operation span multiple data items
- no relational modeling (Shanhe: this is very important)
- data item is small (less than 1 MB)
ACID properties
ACID is properties for database transaction.
Experience at Amazon has shown that data stores that provide ACID guarantees tend to have poor availability[5].
Dynamo has weaker consistency for high availability(C in ACID).
Dynamo has no isolation and therefore only allows single key update.
Efficient
Service should be able to configure Dynamo to achieve tradeoffs among performance, cost efficiency, availability, and durability guarantees.
Security
Non-hostile, no authentication/authorization.
SLA
Amazon is crazy on its SLA due to it is prodiving cloud services. Amazon is not using mean or median of response time, but rather based on the 99.9 th pertenctile of the distrinution.
Design Considerations
Strong consistency is hard (The data is made unavailable until it is absolutely certain that it is correct). To achieve it, the data replication algorithms have to do synchronous replca coordination.
Also we have the CAP therom. so you cannot get three of them all together: network paritions resilience, strong consistency and high availability.
Optimistic replication techniques allows you to propagate changes to replaces. So you gets better availability but you could have conflicting changes which have to be detected and resolved.
Dynamo is designed to be eventually consistent - all updates reach to to all replicas eventaully.
To resolve conflict:
Dynamo targets the design space of an “always writeable” data store (i.e., a data store that is highly available for writes).
- when to resolve them? read or write?
- some system do it at write time
- write can be rejected if the updates are not acked by a majority of replicas
- Dynamo’s choice: Dynamc do this at read time. so writes will never be rejected.
- some system do it at write time
- who to resolve them? data store or application?
- if it is data store, the choice is limited and can only do simple policy, for example “last write wins”
- Dynamo’s choice: application has the better domain knowldege like data schema, it can do merge.
Other design principles:
- incremental scalability: adding one host, has minimal impacts
- symmetry: all nodes are equal. It simplies the system provisioning and maintenance.
- decenralization: try best to avoid simple point of failure. favor peer-to-peer techniques over centralized control.
System Architecture
| Problem | Technique | Adv. |
|---|---|---|
| Partitioning | Consistent Hashing | Incremental Scalability |
| High Availability for writes | Vector clocks with reconciliation during reads | Version size is decoupled from update rates. |
| Handling temporary failures | Sloppy Quorum and hinted handoff | Provides high availability and durability guarantee when some of the replicas are not available. |
| Recovering from permanent failures | Anti-entropy using Merkle trees | Synchronizes divergent replicas in the background. |
| Membership and failure detection | Gossip-based membership protocol and failure detection. | Preserves symmetry and avoids having a centralized registry for storing membership and node liveness information. |
System Interface
- get(key) returns the object or list of objects associated with the key with conflicting version and context.
- put(key, context, object) determins which replicas to write and wrties the replicas to disk.
- context has metadata such as verion, it stores witht the object.
- MD5 hash on the key to get a 128bit idenfitier, used to determine the storage node that should serve the key.
Paritioning Algorithms
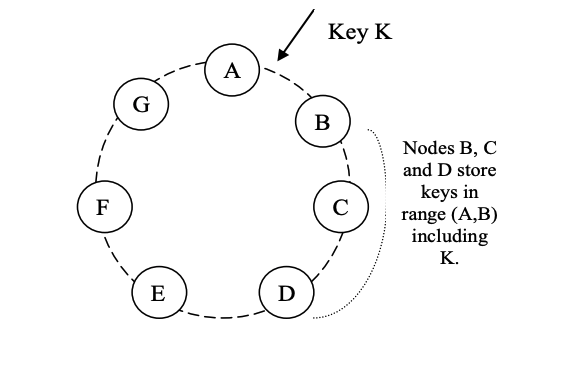
- The main benefits consistency hashing is that departure or add of a node only affects the immediate neighnours. blaster range is limited.
- random position assign leads to non-uniform data and load distrinution. make use of virtual node.
- if a physical node becomes unavailable, the load on this node is evenly dispersed across the reminaing available nodes. (if not using virtual node, the load will be on its next neighbour in the ring, lead to uneven load on that neighbour)
Replication
- Say we want to replicate data on N hosts
- Each key has a coordinator in charge of the repliations.
- The coordinator replicates data also on N-1 succesor nodes closewise in the ring
- skip virtual node of same physical node to make sure the replicate host lists only have distinct physical nodes
Data Versioning
Dynamo provides eventual consistency, which allows for updates to be propagated to all replicas asynchronously.
Put call will return before all replicates apply the update. So a subsequence get call may not have the latest update.
Not all applications suit eventual consistency model. But there is a categoriy of applications in Amazon’s platform can tolerate the inconsistenceis.
- shopping cart, if user sees old shopping cart, may just adjust it, the change is still meaningful
If user modified the data of an old version, there will be a divergent versions that will be reconciled later.
To support this,
- daynamo treat each modification as a new and immutanle version of data. so a key will have multiple version at the same time
- when verion branching happens, and if the system cannot determine the authoritative version (syntactic reconciliation). Then the client need to reconcile the conflict.
- application needs to be designed in a way that is aware that same data can have multiple versions.
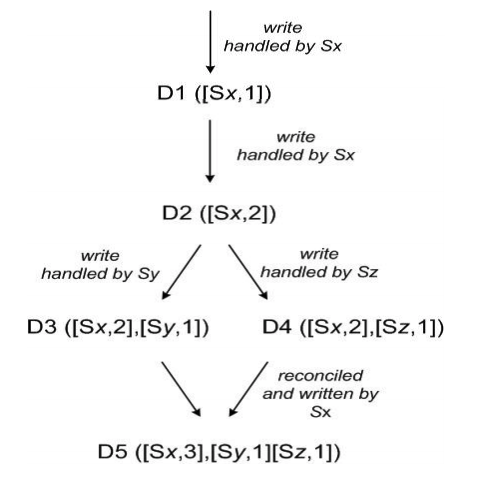
- dynamo uses vector clock to capture causality between differetn versions of same object.
- when client updates a object, it must specify which version it is updaing. this is why there is context, contains the vector clock info.
- when there is multiple version branch that system cannot reconcile, it will return all the obejcts at leaves. An update using this context is considered to have reconciled the divergent versions and the branches are collapsed into a single new version.
A vector clock is effectively a list of (node, counter) pairs. One vector clock is associated with every version of every object. One can determine whether two versions of an object are on parallel branches or have a causal ordering, by examine their vector clocks. If the counters on the first object’s clock are less-than-or-equal to all of the nodes in the second clock, then the first is an ancestor of the second and can be forgotten. Otherwise, the two changes are considered to be in conflict and require reconciliation.
- size of vector clocks can grow.
- In practice, this is not likely because the writes are usually handled by one of the top N nodes in the preference list.
- truncate scheme: store timestamp of lastupdate of each host-counter pair. when it reaches a threshold, the oldest one is removed. (the impact of this truncating has not been thoroughly investigated)
Execution of Get and Put operations
client side selection ndoe
- route request to a load balancer that will select one based on the load information
- may not hit the coordinator, will be forwarded to the coordinator
- use parition-aware client route request directly to the appropriate coordinator nodes
A node handling a read or write operation is known as the coordinator.
To maintain consistency among replicaes. Dynamc uses a quorum system that can be configured: R and W.
- R, minimum number of nodes that must participate in a successful read operation
- W, minimum number of nodes that must participate in a successful write operation.
- R+W > N yield a quorum-like system
when receive a put request,
- the coordinator generates the vector clock for the new version and write it locally
- then coordinator sens the new version to the N highest-ranked reachable nodes, if W-1 node resond then the write is consider successful
for get request
- coordinator requests all existing version of the data from N highest-ranked reachable nodes, waits for R to response before returning the result
- in case of multiple version of the data, it will return all versions if they causally unrelated and expect the divergent version are reconsiled when the reconviled version is written back by application
Handle Failures: Hinted Handoff
sloppy quorum
- all read and write operations are performed on the first N healthy nodes from the preference list, which may not always be the first N nodes encountered while walking the consistent hashing ring.
hinted handoff
- Example: a write to A B C (N=3) if A is temporaily down/unreachable, then the write will be sent to node D, with a hint that A is the intended recipient of the replica.D will put this meta into its local database, when detecint A is recovered, the D will send the replica to A, once the transfer is done, D will delete the object from its local store.
- a method to overcome temporarily failure.
Handle permanent failtures: Replica Synchronization
You could lose a replica and bring up a brand new one, how to make sure it is sync-ed.
- Dynamo uses Merkle tree to detect inconsistencies between replicas and minimize the transferred data.
- Each node maintains one merkel tree for each key range (the key range covered by this virtual node)
- if two nodes host same key range, they can exchange this hash to check if they are sync-ed, or locate the differences and do the synchornization.
- drwaback: node join/leave the system may break the key range, then need to recalculate the Merkle tree (This issue is addressed, however, by the refined partitioning scheme)
Membership and Failure Detection
Ring Membership
due to the system is sensitive to ring membership changes so adding/deleting ring memnership is an explicity workflow done ny the sysadmin.
Use gossip protocol to make sure each node has the up to date memnership.
- when node starts, it chooses set of token (virtual nodes), map nodes to the token sets.
- the mapping is written to local. when two nodes exchange, the membership change hisotries are reconsiled.
External Discovery
the above scheme could temporarily result in a logical partitioned ring. to avoid this need some seed node. Can ne static configuraiton or from a configuration server.
Failure detection
- used to avoid attempts to communicte with unreachable peers
- decentralized failure detection
Adding/Removing Storage Nodes
add nodes will take onwnership of keys from other nodes. and vice versa when removing nodes.
doing this due to the need of distributing keys uniformly across storage nodes.
Implementation
three main components
- request coordination,
- event drive messageing system with multiple stage message processing pipeline SEDA
- Java NIO
- each request is managed by a state machine
- read operation has the following state machine implemented
- send read requests to nodes
- wait for minimum number of requested responses
- if too few replies were received within the given time, fail the request
- otherwise, gather all data version and determin the one to return
- if versioning is enabled, do syntatic reoconciliation and generrate an opaque write contains the sutiable vector clock
- read operation has the following state machine implemented
- membership and failure detection
- a local persistence engine
- pluggable persistence component support multiple storage backend.
Expriences and Lessions Learned
main patterns Dynamo is used
- business logic specific reconciliation, e.g., shopping cart merges different versions
- timestamp based reonciliation
- high performance read engine, many reads and a few writes.
Balancing Performance and Durability
Clients can tune N, R, W to achieve the deseried levels of performance, availability and durability.
Ensuring Uniform Load Distribution
In a given time window, a node is considered to be “inbalance”, if the node’s request load deviates from the average load by a value a less than a certain threshold concept of imbalance ratio: fraction of nodes that are “out-of-balance” during this time period
Partitioning schema
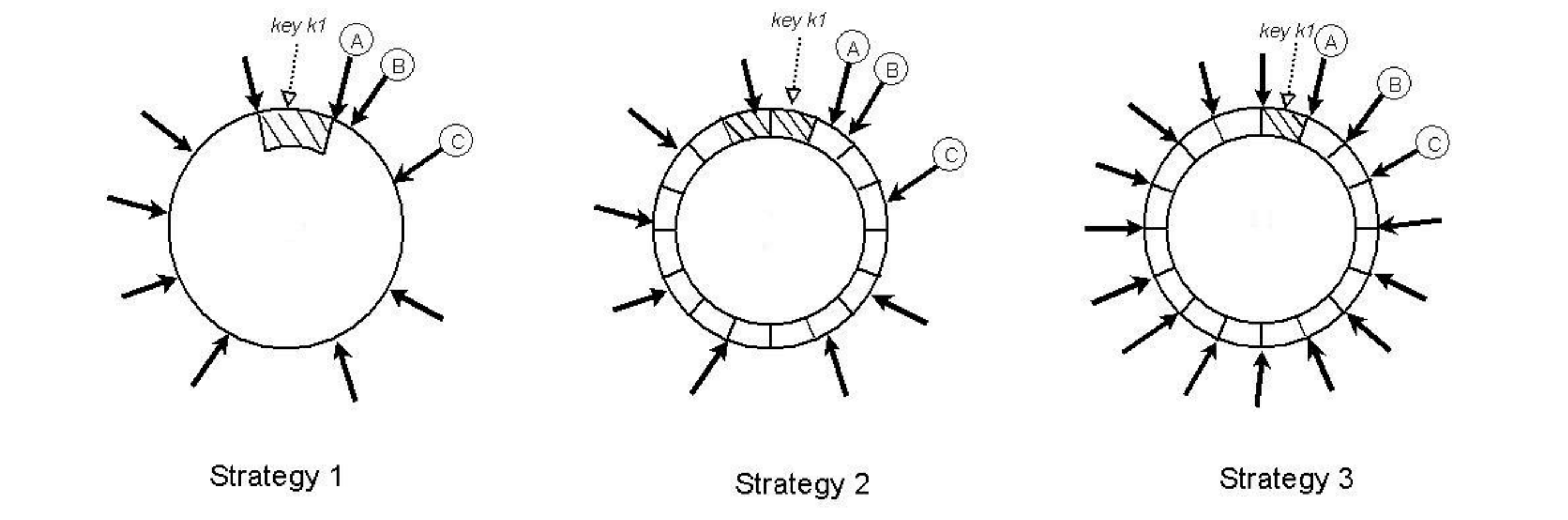
Strategy 1: T random tokens per node and partition by token value
- each node is assigned T tokens, unifomly randomly selected from hash space
- tokens are all sorted, every two consecutie tokens defined a range.
- the range varies in size
- when a node joins,
- it needs to “steal” key ranges from other nodes. The node need to scan its local store to do that, which is resource intensive in production.
- the merkel tree used for replica meta has to be recalculated
Strategy 2: T random tokens per node and equal sized partitions
- divides hashspace to Q equallized size ranges, and each node is assigned T random tokens (Q » S*T, S is the number of nodes in the system)
- the tokens doesnt decide paritioning anymore, it just define the mapping values into the hash space.
- A parition is placed on the first N unqiue nodes, that are encounter while walking on the ring
- adv
- decoupling of partitioning and parition placements
- enabling the possibiliy of changing the placement schema at runtime.
- dis
- when node join/leave happens, the load may not be even distributed. the cost goes as more metadata maintained.
Strategy 3: Q/S tokens per node, equal-sized partitions
Similar to strategy 2, this strategy divides the hash space into Q equally sized partitions and the placement of partition is decoupled from the partitioning scheme. Moreover, each node is assigned Q/S tokens where S is the number of nodes in the system. When a node leaves the system, its tokens are randomly distributed to the remaining nodes such that these properties are preserved. Similarly, when a node joins the system it “steals” tokens from nodes in the system in a way that preserves these properties.