[VLDB'20] Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores
Data Lake is a hot word for a while. By reading this paper, I am trying to figure out what is new here, what are the new requirments here lead to this Data Lake concept, what are the data lake solutions we can have (This might be a follow up post to compare Delta Lake with Apache Hudi, and Apache Iceberg.
Cloud Object Stores, like S3 Azure Block Storage etc, or S3-api-compatible object store like minio, etc. are designed to store what ever kind of data.
Many big data system components, like Apache Spark, Hive, Presto, can read/wirte to object sores. using file format like, Apache Parquet, ORC.
The exiting challegens of such systems are
- performant and mutable table storage is hard
- most object stores are just key-values, no cross key consistency guarantees
- performant consistency is hard
- relational datasets are stored into cloud object sotres using columnar file formts such as Parquet, ORC, (e.g., Hive)
- performance/correctness when more complex workload
- multiple objects update are not atomic, no isolation for query
- rolling back writes is hard
- relational datasets are stored into cloud object sotres using columnar file formts such as Parquet, ORC, (e.g., Hive)
Give thtat move enterpsie datasets are continously updated, and also some GDPR compliance requirements, there is a requirement for atomic writes.
To address these challenges, Databricks designed Delta Lake, an ACID table storage layer over cloud object stores.
The basic idea is
- maintain metadata of objects in an ACID manner
- using a write-ahead log (WAL) in the cloud object store
- objects encoded in Parquet
- allow multiple clients to update, replace,
- the log also cotains min/max statictics for each data file, so enabling order/search efficiently.
- transaction via optimistic concurrentcy protocols
Thus these features can be added
- Time travel, let users query point-in-time snapshots or roll back data
- UPSERT, DELETE, MERGE
- Efficient streaming IO
- let streaming job wrtie small objects into the table by low latency, then coalescing them into larger objects later for performance (Shanhe: many system has such compaction feature)
- fast tailing reads of new data is also supported, so it can be used as a message bus. (Shanhe: this is cool)
- Cache
- Data layout optimization , optimize the size of the object, and clustering data records without impacting running queries. (move records in object around for some purposes)
- Schema evolution, can read old Parquet files without rewrite them if table’s schema changes.
- Audit logging based on transaction log.
Motivation
Object Store APIs
Object store is easy-to-scale key-value store.
It is not file system. (It is common to model keys after file system paths (e.g., warehouse/table1/part1.parquet), but it is not file system), the list operation is provided via metadata APIs
These metadata APIs are expensive. E.g., S3 list takes minutes to list dataset with millions of objects in a sequential implemetnation.
Update needs to overrite the whole object at once.
Consistency Properties
the object store provides eventual consistency for each key. No consistency guarantee across keys.
The exact consistency model differs by cloud provider, and can be fairly complex.
Performance Chracteristics
For read, read incurs 5-10ms latency, and read data at 50-100MB/s, however the nework is 10Gps, need 8-10 parallel to fully utilize the network bandwidth.
LIST needs significant parallelism to list large set of objects.
Write has to repace the whole object.
Implications for Table Storage
when we have analytic workoad, according to the performance charactersitcs of object store, we have these considerations
- keep frequent access data close-by sequentially, this leads to columnar formats
- make object large but not too large, large object increases update cost, due to fully rewritten
- avoid LIST operations, make mke it requests lexicographic key ranges when possible
Existing Approach for Table Storage
Directory of Files
columnar format such as Parquet.
Adv
- a bunch of objects can be accessed from mana tools without running any additional data stores/systems.
Drawbacks
- no atomicity across multiple objects.
- eventual consistency
- performance: list
- not management functionally such as table version or audit logs
Custom Storage Engines
A close-word storage engine.
E.g., Snowflak data warehouse. manage metadata in a separtae strongly consitency service.
- metadata service is the bottleneck,all operations to table need to contact metadata service
- need connectors to exiting compute engines
- vendor lock-in
Hive has a metastore (via a transtactinal RDBMS) to keep track of multiple files tha thold update for table stored in ORC format. This appraoch limited by the performance of the metastore (Shanhe: I think Databricks tries to emphasis that the solution has to be a cloud solution, otherwise hard to scale.. But they will basically solve it along this direction with a metadata store service)
Metadata in Object Stores
This is Delta Lake’s appraoch. Built this metadat and transtaction log within the cloud object store.
The data are also stored via Parquet. Apache Hudi and Apache Iceberg also follows this.
Delta Lake Storage Format and Access Protocols
Storage Format
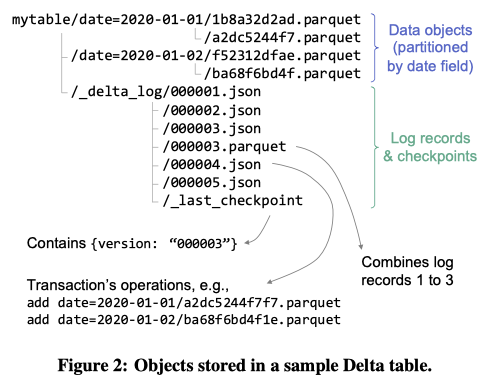
Data Objects
Data objects organized using Hive’s parition naming convention. For the example given, it is paritioned by the data column, so the data objects are in separate directories for each date.
Choose Parquet due to widely adoption and mature support from not just Spark but also other engines.
Log
The log is put in _delta_log subdirectory. Log record is in json. Parquet format is used to create checkpoint that summaried up the log to that point.
Each log record contains an array of actions that apply to the previos version of the table
The avaialbe actions are
- Change MetaData
- metadata is a data structure containing schmea, partition column names (e.g., the data column showed in this example) if the data is partitioned, the storage format of data files, other configurations etc
- Add or Remove a file
- add reocrd can also contains data statistics, such as total record count, or per column min/max
- statistics are replacing previous
- only statistic update is allowed (Shanhe: If I understand it correctly)
- remove action includes a timestamp
- real deletion happens lazily via tombstone
- dataChange flag to help query to skip actions that would not affect ther result
- add reocrd can also contains data statistics, such as total record count, or per column min/max
- Protocol Evolution
- used to check client compatiability
- Add Provenence Information
- commitInfo, e.g., which user did the operation for audit purpose
- Update Application Transaction IDs
- application can include data in the transactional log
- e.g. streaming processing write to the system needs to know which of the writes has been previously commited in order to achieve exactly-once semantics: if it crashes, it needs to know what has been written
- DeltaLake allows applications to write ac sustom tx action with appId, and version fields in the log record to track application specific info, such as offset in streaming processing write
- this info will be placed together with add/remove, that are inserted into the log atomically.
- application can include data in the transactional log
Log Checkpoints
Peridoically compress the log into checkpoints can help with the performance
during the compression into a Parquet file
- add followed by a remove for the same data object.
- the add can be removed
- the remove is kept as tombstone
- multiple adds for the same object can be replaced by the last one, since new add will only add statistics
- multiple txn for same appId can be replaced by last one, which has latest version field
- changeMetaData and protocol can also be coalesced to keep only the latest metadata.
The parquet name will sue the log record id it checkpoints up to.
In order to support tailing log without LISTING all objects
_delta_log/_last_checkpointfile wil be written if it is newer than the current ID in that file.
Access Protocol
Reading from Tables
Read-only transactions steps
- Read the
_last_checkpintif exists, obtain a recent checkpoint ID - Use LIST operation with start key is the last checkpoint ID if present, or 0 otherwise. to get any newer
.jsonand.parquetfiles in the log directory. Due to eventual consistency, the client may get non-contiguous set fo objects. However the clietn can use the largest ID returned as a version to read and wait for missing object become visible. - Use the checkpoint and subsequence log to reconstruct the state of the table i.e., set of objects that have add records, but no corresponding remove records. The task can be ran in parallel, in Spark jobs.
- Use statistics to indentify the set of data object files relevant for the read query
- query the object stores toread relevant data objects. Due to eventual consistency, some of the object may not be available, can simply retry after a short amount of time.
Write Transactions
- Identify a recent log record Id
r, using steps 1-2 of the read protocol. Then read data at table versionrand attemp to write log recor dr+1 - read data at table version
r - write any new data objects that the transaction aims to add into a new file, generate object name using GUIDs.
- Attemp to wrtie the transaction’s log record into
r+1.json, if no client has written this object. This step needs to be atomic. If fails, the tranaction can be retried - Optionally, write a new
.parquetcheckpoint file for log recordr+1, after the write point_last_checkpointfile to the checkpointr+1.
Adding Log Records Atomically
Not all object store has atomic put-if-absent operations.
- Google Cloud Storage and Azure Blob Sotre support atomic put-if-absent
- HDFS, we use atomic renames to rename a temporary file to the target name. Azure Data Lake Storage offers a filesystem API with atomic renames
- Amazon S3 has not such semantic. Use a lightweight coordination service toensure only one client can add a recor dwith each log ID. In the open source version, it uses single writer using in-memory state.
MISC
Given Delta Lake’s concurrency control protocols, all transactions that perform writes are serializable, leading to a serial schedule in increasing order of log record IDs. This follows from the commit protocol for write transactions, where only one transaction can write the record with each record ID. Read transactions can achieve either snapshot isolation or serializability.
Delta Lake’s write transaction rate is limited by the latency of the put-if-absent operations to write new log records
High Level Features in Delta Lake
Time Travel and Rollbacks
Data objects and log are immutable, using MVCC implementation.
A client simply needs to read the table state based on an older log record ID.
To suppor time travel, per-table data retention interval.
Efficient UPSERT, DELETE and MERGE
With Delta Lake, all of these operations can be executed transactionally, replacing any updated objects through new add and remove records in the Delta log. Delta Lake supports standard SQL UPSERT, DELETE and MERGE syntax.
Streaming Ingest and Consumption
There some message queue supports
- Wrtie Compaction
- Exactly-Once Streaming Writes
- Efficient Log Tailing
Data Layout Optimiazation
- OPTIMIZE to compacts msall objects.
- make each object 1GB in size by default
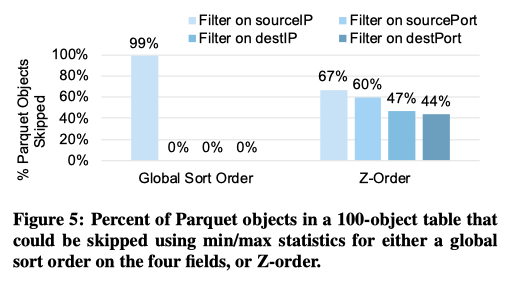
- Z-Ordering by Multipel Attributes
- The Z-order curve is an easy-to-compute space-filling curve that creates locality in all of the specified dimensions.
- reorg records in table in Z-order along a given set of attributes to achieve high localiy aong multiple dimensions
- AUTO OPTIMIZE automatic compaction
Cachcing
At Databricks, we built a feature to cache Delta Lake data on clusters transparently, which accelerates both data and metadata queries on these tables by caching data and log objects. Caching is safe because data, log and checkpoint objects in Delta Lake tables are immutable.
Audit Logging
Users can view the history of a Delta Lake table using the DESCRIBE HISTORY command
Schema Evolution and Enforcement
Keeping a history of schema updates in the transaction log can also allow using older Parquet objects without rewriting them for certain schema changes (e.g., adding columns). Equally importantly, Delta clients ensure that newly written data follows the table’s schema.
Connectors to Query and ETL Engines
Delta Lake provides full-fledged connectors to Spark SQL and Structured Streaming using Apache Spark’s data source API. In addition, it currently provides read-only integrations with several other systems: Apache Hive, Presto, AWS Athena, AWS Redshift, and Snowflake, enabling users of these systems to query Delta tables using familiar tools and join them with data in these systems. Finally, ETL and Change Data Capture (CDC) tools including Fivetran, Informatica, Qlik and Talend can write to Delta Lake.
Delta Lake Use Cases
customers often use Delta Lake to simplify their enterprise data architectures, by running more workloads directly against cloud object stores and creating a “lakehouse” system with both data lake and transactional features.
- Computer System Event Data
- Bioinformatics
- Media Datasets for Machine Learning
Performance Experiments
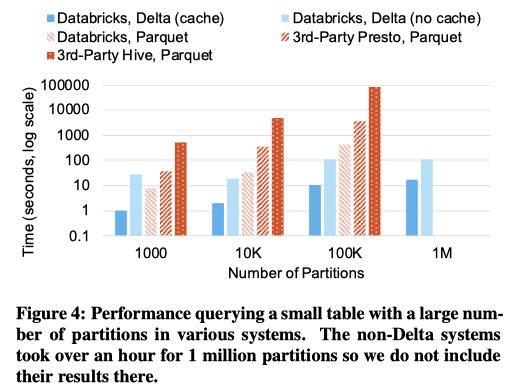
Impact of Many Objects or Partitions
Impact of Z-Ordering
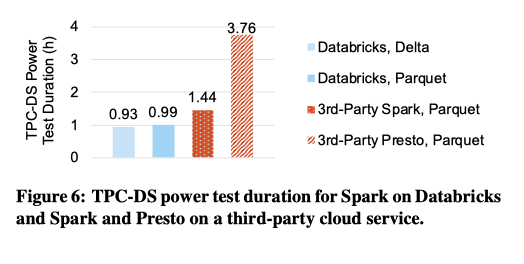
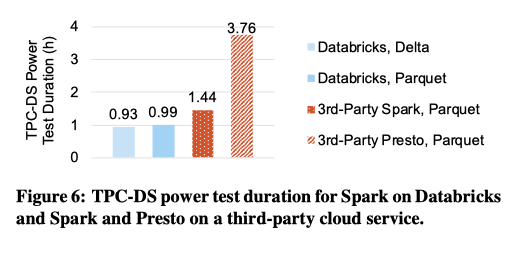
TPC-DS Performance
Eacy system ran one master and 8 workers on i3.2xlarge AWS VMs, which have 8 vCPUs each. We used 1 TB of total TPC-DS data in S3, with fact tables partitioned on the surrogate key date column.
Write Performance
a 400 GB TPC-DS store_sales table, initially formatted as CSV, on a cluster with one i3.2xlarge master and eight i3.2xlarge workers (with results averaged over 3 runs).
Limitations
First, Delta Lake currently only provides serializable transactions within a single table, because each table has its own transaction log
Second, for streaming workloads, Delta Lake is limited by the latency of the underlying cloud object store.
Third, Delta Lake does not currently support secondary indexes (other than the minmax statistics for each data object), but we have started prototyping a Bloom filter based index.
Shanhe’s Reflections
Is there anything new?
Yes. I think the core contribution is to identify the usecase for modern dataware houses/data lakes. E.g., that we need not just a object store that can hold all the data. We also need feature such as ACID and some of the upper layer features to be present at this layer, to fulfil the usecase of data lakes.
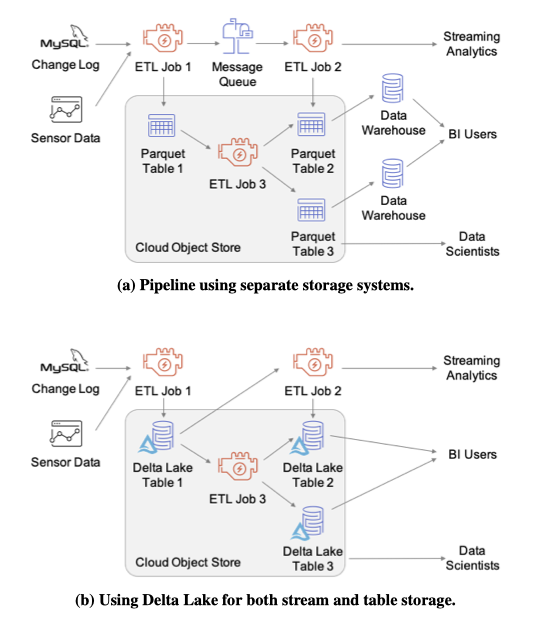
It is more like we already have these components or sub-problems solved at different layers. But now, we decide these components need to go in in order to build this data lakes.
Like showed in this figure, the benefits of this new abstraction can lead to simplification of the systems.
Who shoud not use Delta Lake
- No need ACID transaction
- simple data model, suites to the key-value underneath cloud object store
- Not in use of cloud object store as data warehouse
- as the Delta Lake is seeking cloud object store native solutions
- consider Hive Metastore or built similar in-house