understanding back propagation
接下来的posts可能会focus在deep learning这一块,可能是真的太火了,觉得自己也得具备这个基本的知识库。 自己也算是初学, 望大家指点。
在neutral network的training中 back propagation 算法很关键 我的学习方式是决定直接读 Hindon的那片文章 《Learning representations by back-propagating erros》
对于learning system的描述 直接翻译一小段
最简单的分层网络学习过程通常是:最低层是输入单元, 有任意数目的中间层, 最高层是输出单元, 每一层内单元的不会有互联, 也不会有跨层的互联,但是可以跳过这些中间层。 一个输入向量就是设置输入单元的状态。 每一层的单元的状态就是根据底下一层的输出当作输入由方程(1)和(2)来计算。 每一层的计算被当作是并行, 但是层与层之间是串行, 这样自底往上的计算知道输出单元被决定。
假设 一个 linear 的系统 input-output function
到state的mapping输出 通常是一个non-linear函数
其实觉得这里的notation不是很好,不利于后面的思考,读者不妨把
想象成是当前层, 而 是之前的那一层就行了 这里的意思就是说 前一层的输出经过加权就是这一层的输入, 然后再经过方程(2)转成这一层的输出, 方程(2)相当于模拟了神经元 这是一个sigmoid函数 方程(1)还可以加bias这里为了简洁没有写入. 根据 Hinton的 paper 里说的, 第一个函数可以是任意的, 只要有 bounded derivative, 但是一般用一个linear function来combine inputs 到一个unit再用 non-linear 能够简化这个学习的过程。
那么学习的过程其实就是找到一组 weights 能够确保 每一组输入对应的输出能够尽最大可能的贴近真值。
如果有有限的输入和输出, 那么总的错误
其中
要想最小化
这里有一个 forward pass 是 equations (1)和(2): 每一层的states是尤其从前一层得到的输入来决定的
而 back pass 是指从最高层到最低层来传播的。
back pass 始于 从 Error function (3)
这里有求导的 chain rule 因为我们知道
带入方程 (2)
很多年没做过chain rule求导了 差点脑死亡
结果是稍作变形
这个结果的含义是 我们知道了 当前层的
同样的 对于
表示 weight
此外还有 前一层 unit
所以做一个summation就是前一层unit
现在我们知道如何为倒数第二层计算
因为
因此我们可以不停的向前计算
结合当前层和前一层之间的权重得到前一层
一开始 weight 都是 random 选取的
更新 weight 的方式, 有每输入一组input-output case就更新 这样不需要存导数
另一种是在输入 input-output case的过程 先accumulate
这里就用梯度下降每次减少一点点
一种改进是 用当前的gradient来修改其在 weight space 的速度而不是position
Example
接下来 用代码来验证一下 代码中标记了和上面方程式的对应关系。
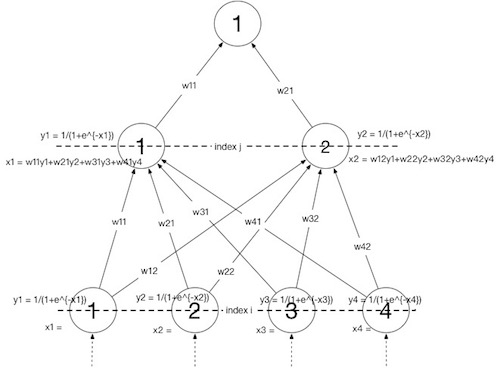
Network如图
Code
{% gist yishanhe/79f06cfa94b0e692698a %}
cost output
[ 0.02553798]
[ 0.02085472]
[ 0.01765256]
[ 0.01538757]
[ 0.01374046]
[ 0.01251489]
[ 0.01158523]
[ 0.01086832]
[ 0.01030757]
[ 0.00986344]
[ 0.00950775]
[Finished in 0.393s]