[ICDE'20] Turbine: Facebook's Service Management Paltform for Streaming Processing
@inproceedings{mei2020turbine,
title={Turbine: Facebook’s Service Management Platform for Stream Processing},
author={Mei, Yuan and Cheng, Luwei and Talwar, Vanish and Levin, Michael Y and Jacques-Silva, Gabriela and Simha, Nikhil and Banerjee, Anirban and Smith, Brian and Williamson, Tim and Yilmaz, Serhat and others},
booktitle={2020 IEEE 36th International Conference on Data Engineering (ICDE)},
pages={1591--1602},
year={2020},
organization={IEEE}
}
从这一篇开始,争取每一个月精读一篇来自工业届的system paper.
Stream processing systems are becoming popular
MillWheel, Storm, Spark Streaming, Heron, Samza, Dataflow, Flink, Kafka Streams.
Stream processing systems challenges
- fault tolerance: Storm
- low latency: Flink, Storm
- operability: Storm
- expressive programming model: MillWheel
- processing sematic: Dataflow
- scalability: MillWheel
- effective resource provisining: Heron
- statful streaming: Samza, Spark Streaming, Kafka Streams, Flink.
What is the limitation of alternative solutsion?
Existing general-purpose cluster management systems such as Aurora [1], Mesos [15], Borg [33], Tupperware [25] and Kubernetes [10] satisfy common management requirements across a variety of workloads but are not necessarily tuned for stream processing needs since they are designed based on different assumptions and use cases.
YARN [30] is a resource manager adopted by many stream processing systems including Flink [11], Samza [26], Spark Streaming [35] and StreamScope [23]. They mostly provide resource isolation and enforcement framework which works best if resource requirements can be determined in advance.
YARN is a two-layer resource negoiator that you need to know what you need bofore negoiating, and lack of support for auto scaling.
What is the Turbine
- a service management platform that can be layered on top of the general-purpose frameworks listed above to provide specialized capabilities for stream processing applications.
- integrated with Tupperware, a Borg like cluster management system.
- minimize down time and meet SLO
- auto scaling
- fast scheudling
- Turbine provides an atomic, consistent, isolated, durable, and fault-tolerant (ACIDF) application update mechanism.
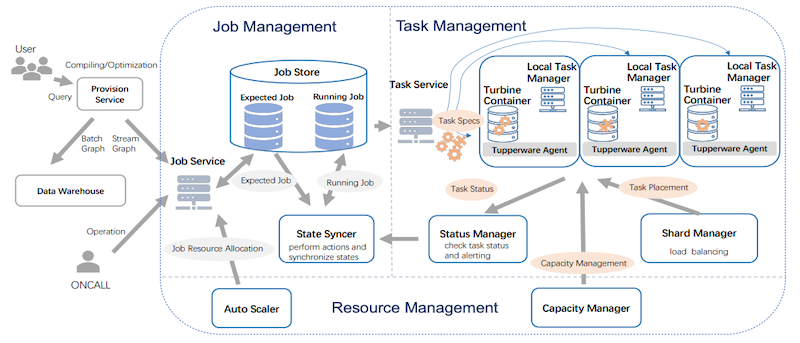
- Turbine architecture decouples what to run (Job Management), where to run (Task Management), and how to run (Resource Management).
System Overview
| Layers | Charges |
|---|---|
| Job Management | job config, job update |
| Task Management | convert job to tasks, schedule, and load balance tasks to clusters |
| Resource Management | adjust resource allocation to a job, a task and a cluster in real time |
- a job can have multiple tasks, that run same binary in parallel, each task process deals with a disjoint set of input.
- Communication between jobs is done by FB’s persistent message bus - Scribe.
- Each task of a job will read one or serveral disjoint data paritions from Scribe, maitain state and checkpoint. So failed task can recover.
- Turbine’s data model eliminates dependencies between tasks.
Job Management
Keep job up-to-date, in ACIDF fashion.
- Job Store, repository for current and desired configuration parameters for each job
- Job Service, guarantee job changes are commited atomically
- Job Syncer, drive job from current state to desired sate.
Hierarchical Expected Job Configuration
In Turbine, a job can be updated by different internal services or users at the same time.
- Configuration is defined by Thrift for compilation type checking.
- During runtime, convert to JSON.
- Multiple JONs can be layered.
- Using a generic JSON merge to recursively merge the JOSNs, top overrirdes bottom.
State Syncer
- sync expected, and running configs every 30s
- generate execution plan if there are differences
- batch simple synchronizations and parallelize the complex ones
Complexy Synchronization: Changing job parallelism, for instance, requires multi-step synchronizations: the State Syncer stops the old tasks first; once all the old tasks are completely stopped, it redistributes the checkpoints of the old tasks among the future new tasks, and only then starts the new tasks. If a complex synchronization fails in the middle, the State Syncer reschedules it in the next synchronization round within 30 seconds. If it fails for multiple times, the State Syncer quarantines the job and creates an alert for the oncall to investigate
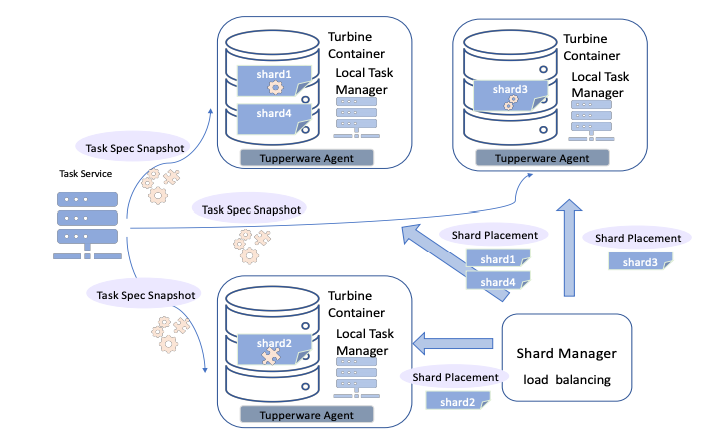
Task Placement and Load Balancing
Goals:
- no duplication, since failed task can recover
- fail over task to healthy host during host failures
- restart tasks upon crashes
- load balancing among hosts
Integrate with container manager
- Each container runs local manager that spawns a subset of stream processing taksk within the container.
- local manager periodically fetches latest full snapshot of Task specs
- Task specs are onfigurations needed to run the task. They are generated by Task Service, via template substitutions.
Shanhe: Hey, think, this can map to the kubernetes model for sure. A k8s operator can just do this.
Scheduling
Task to Sharding Mapping
Turbine uses Facebook’s Shard Manager service (similar to Google’s Slicer [6])
- Each of the local Task Managers is responsible for determining which tasks are associated with the shards it hosts
- MD5 of the task, defines the shard ID
Shard Movement
- When Shard Manager decides to reshuffle, DROP_SHARD is sent to Task Manager
- Task Manager find task that associated with the dropped shar, move the shard from its local bookeeping structure and return SUCCESS
- Shard Manager update the mapping of shards to container, and send ADD_SHARD
- Task Manager will adds the new shards to its local bookeeping structure.
Load Balancing
The algorithm to generate the shard to Task container mapping does a bin-packing of shards to Turbine containers such that the capacity constraint of each Turbine container is satisfied while also a global resource balance is maintained across the cluster.
Failure Handling
Turbine uses a bi-directional heartbeat-based fail-over protocol with the Shard Manager. When the Shard Manager does not receive a heartbeat from a Task Manager for a full fail-over interval (default is 60 seconds), it assumes the corresponding Turbine container is dead, generates a new mapping for the shards in that container, and invokes the shard movement protocol
handling Connection failures from system failture - do a reboot to see if it can recover.
Elastic Resource Management
Resource management is responsible for reacting to load changes at task level, job level and cluster level. It has two goals: (i) ensure that all jobs have sufficient resources needed for processing their input on time, and (ii) maintain efficient cluster-wide resource utilization.
Reactive Auto Scaler
Detect Lag
- esimate the time lagged.
$$ t_{lagged} = \frac{D}{P} $$
where $D$ is total bytes lagged, and $P$ is processing rate.
Detect OOM
- For tasks running in containers with configured cgroup limits, cgroup stats are preserved after OOM tasks are killed. Upon restarting such tasks, Turbine task managers read the preserved OOM stats and post them via the metric collection system to the Auto
- For Java tasks, JVM is configured to post OOM metrics right before it kills the offending tasks
Problems
- taks too long to get a stable state due to lack of accurate estimate
- no lower bound, cannot make good downscaling decisions
- making scaling decisions without understanding the root cause of a particular symptom may amplify the original problem
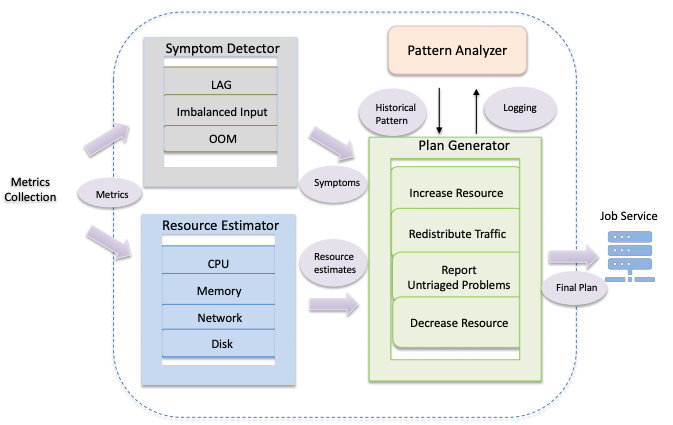
Proactive Auto Scaler
Estimate/Predict instead of measure
| job state | common operation |
|---|---|
| Stateful | aggreagtion, join |
| Stateless | filtering, projection, transformation |
For Stateless job, it is CPU intensive, and CPU consumption is proportional to the size of input and output
For input $X$, the CPU resource needed is
$$ \frac{X}{P \cdot k \cdot n} $$
where $P$ is the maximal processing rate for a single thread. $k$ is the number of threads per task, $n$ is the number of parallel tasks.
If there are backlogs $B$ needs to recovered within time $t$
$$ \frac{X + B/t}{P \cdot k \cdot n} $$
For stateful job, additionally, also needs to estimate memory and disk usage.
- aggregation, memory is propotinal to the key cardinality
- join operator, the memory/disk size is propotinal to the join window size, the degree of input matching, and degree of input disorder
Plan Generator makes a synthesized decision based on symptoms and resource estimates collected.
Preactive Auto Scaler
Use pattern analyzer to prune out potentially destabilizing scaling decisions
Two set of data
- resource adjustment data
- historical workload pattern