Reading Note on 'Designing Event-Driven Systems'
This is the freebook I got from official website of Confluent, written by Ben Stopford. I like his website, there are lots of interesting stuffs.. and this book is also on his website with pdf, epub and mobi.
Trend of Microserves and How Kafka came into the picture
It starts with Amazon, and according to Steve Yegge’s Google Platform Rant post, the one of the a few things that Amazon has done right than Google.
All teams will henceforth expose their data and functionality through service interfaces.
Teams must communicate with each other through these interfaces.
There will be no other form of interprocess communication allowed: no direct linking, no direct reads of another team’s data store, no shared-memory model, no back-doors whatsoever. The only communication allowed is via service interface calls over the network.
It doesn’t matter what technology they use. HTTP, Corba, Pubsub, custom protocols – doesn’t matter. Bezos doesn’t care.
All service interfaces, without exception, must be designed from the ground up to be externalizable. That is to say, the team must plan and design to be able to expose the interface to developers in the outside world. No exceptions.
Anyone who doesn’t do this will be fired.
Then Netflix.
Then Linkedin, changed its monolithic Java application into 800-1000 services. One different here is that Linkedin uses a in house built message/replyable log system: Kafka.
HTTP interfaces make lookup simple, but not moving data around.
Replayable logs decouple services from one another, much like a messaging system does, but they also provide a central point of storage that is fault-tolerant and scalable—a shared source of truth that any application can fall back to.
Clustering streaming is built upon Kafka repliable logs.
Kafka is a mechanism for programs to exchange information, but its home ground is event-based communication, where events are business facts that have value to more than one service and are worth keeping around.
Chapter 5 Events: A Basis for Collaboration
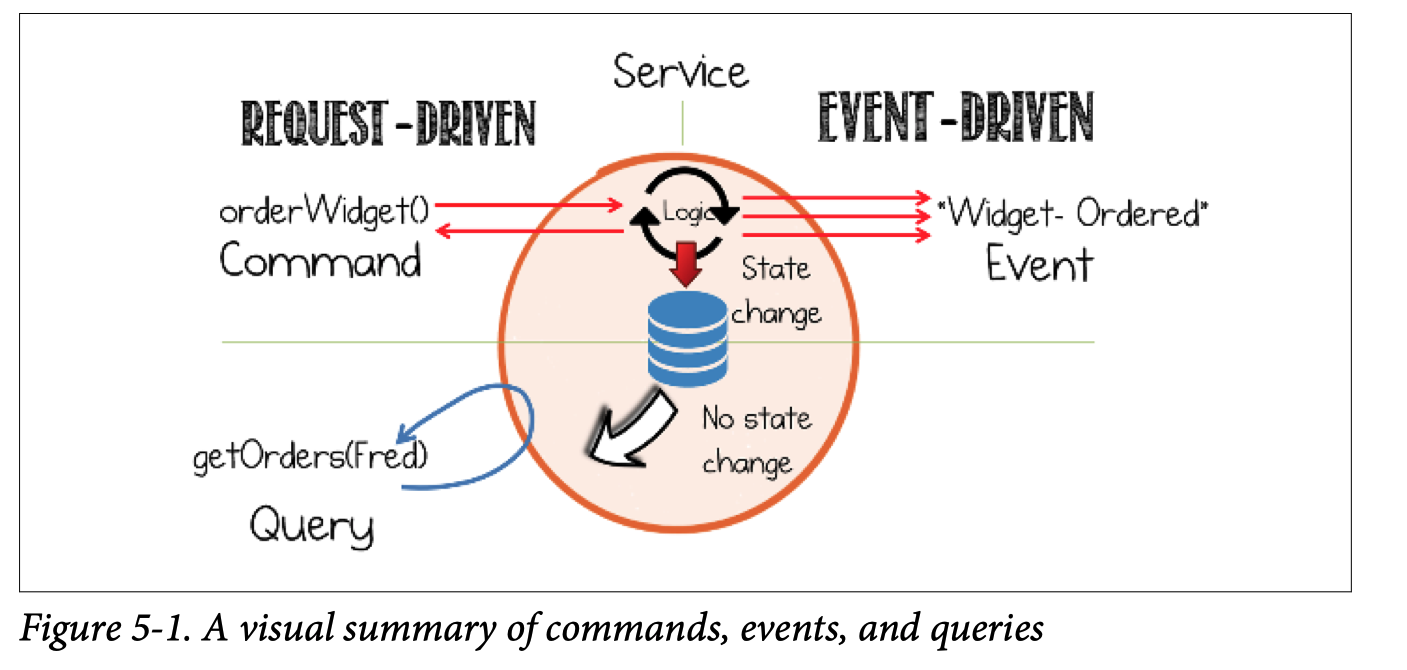
Commands
Commands are actions—requests for some operation to be performed by another service, something that will change the state of the system. Commands execute synchronously and typically indicate completion, although they may also include a result.
Events
Events are both a fact and a notification. They represent something that happened in the real world but include no expectation of any future action. They travel in only one direction and expect no response (sometimes called “fire and forget”), but one may be “synthesized” from a subsequent event.
Queries
Queries are a request to look something up. Unlike events or commands, queries are free of side effects; they leave the state of the system unchanged.
Coupling and Message Brokers
Fran Leymann: Loose coupling reduces the number of assumptions two parties make about one another when they exchange information.
Both values are in loose and tight coupling
Loose coupling lets components change independently of one another. Tight coupling lets components extract more value from one another.
Sharing always increases the coupling on whatever we decide to share.
Messaging provides loose coupling.
Essential Data Coupling Is Unavoidable
Functional couplings are optional. Core data couplings are essential.
From request driven to event driven system.
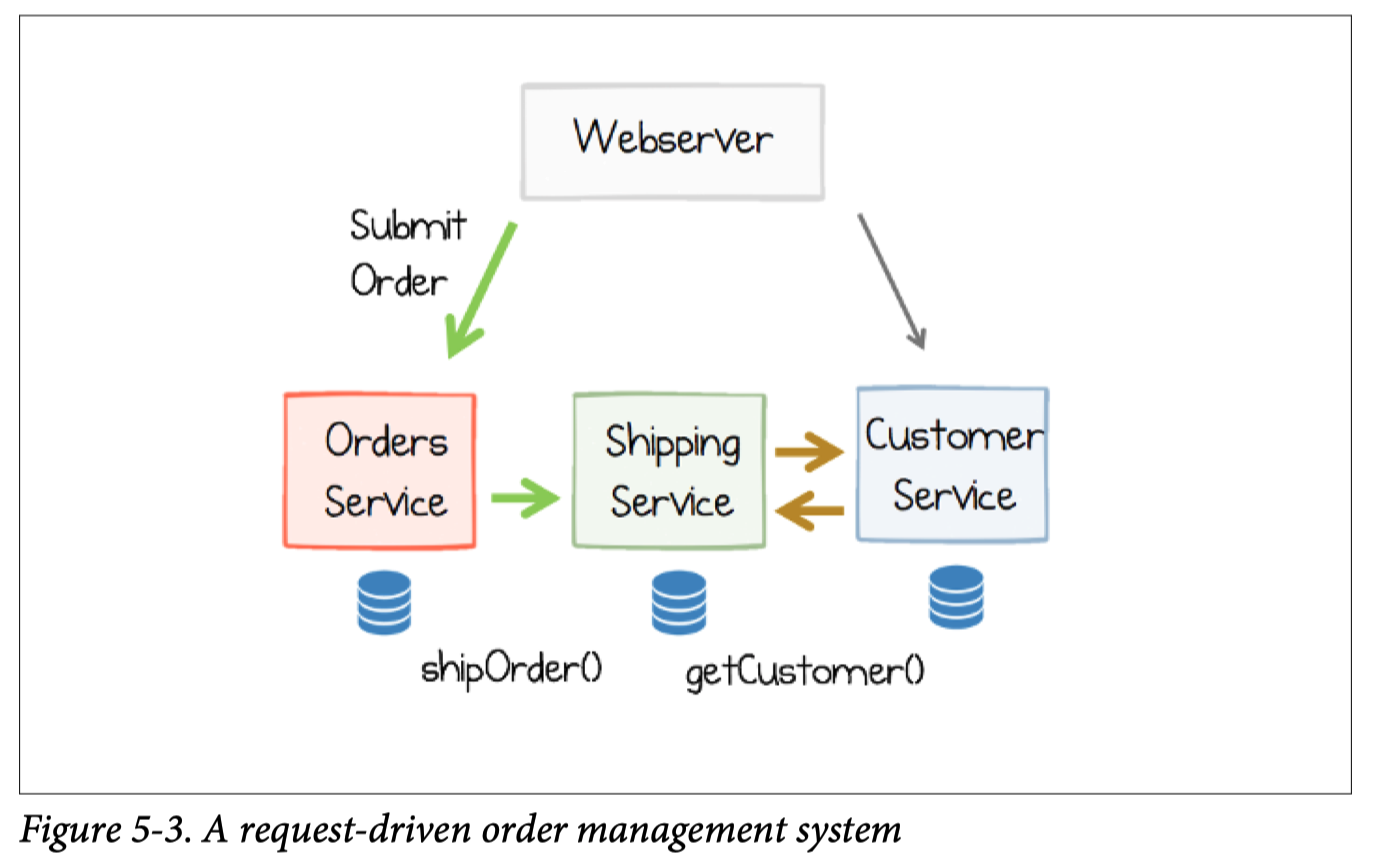
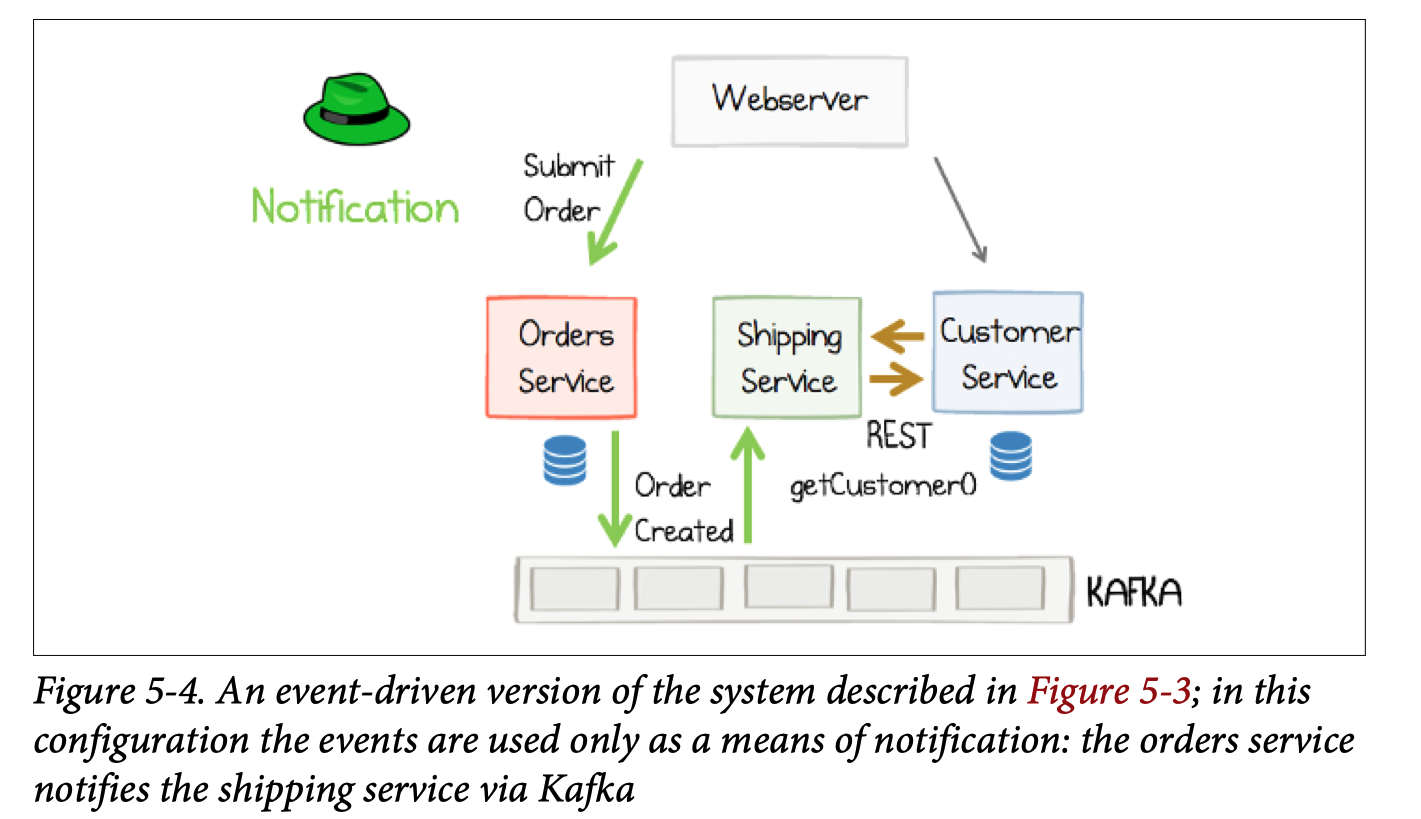
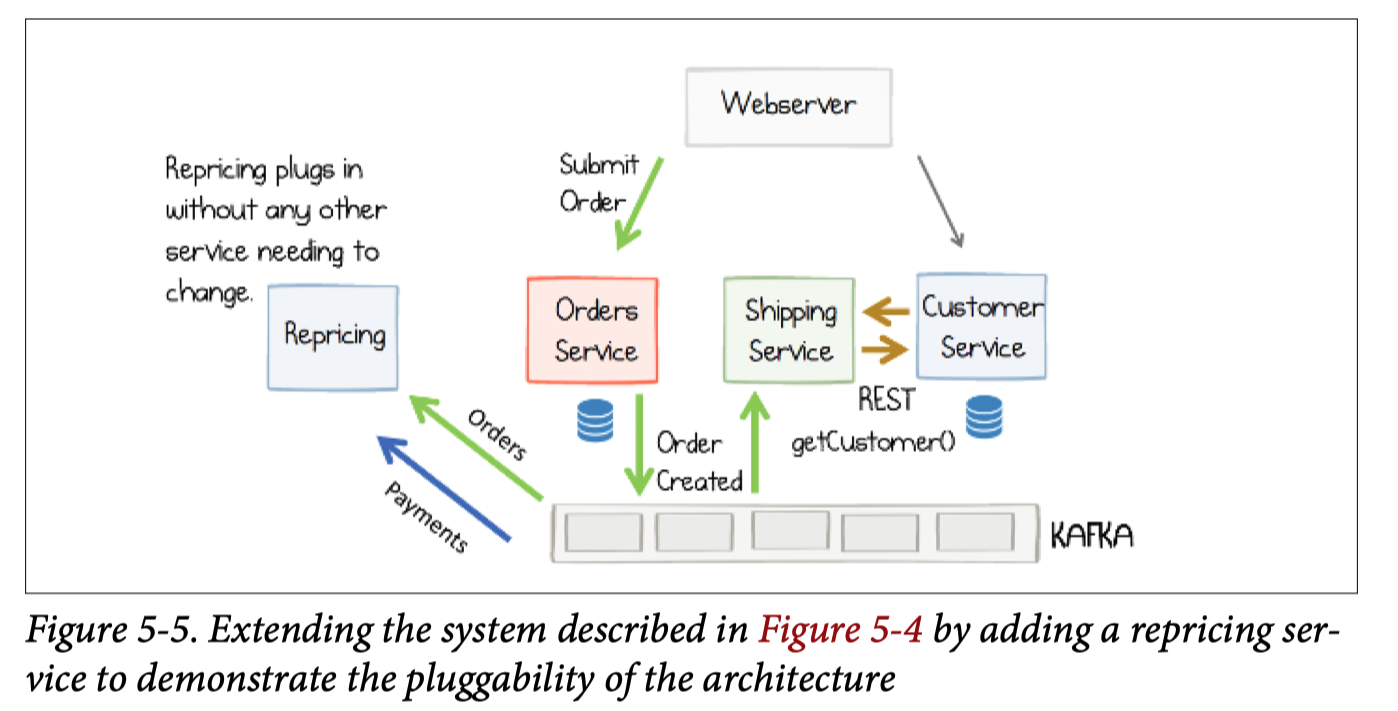
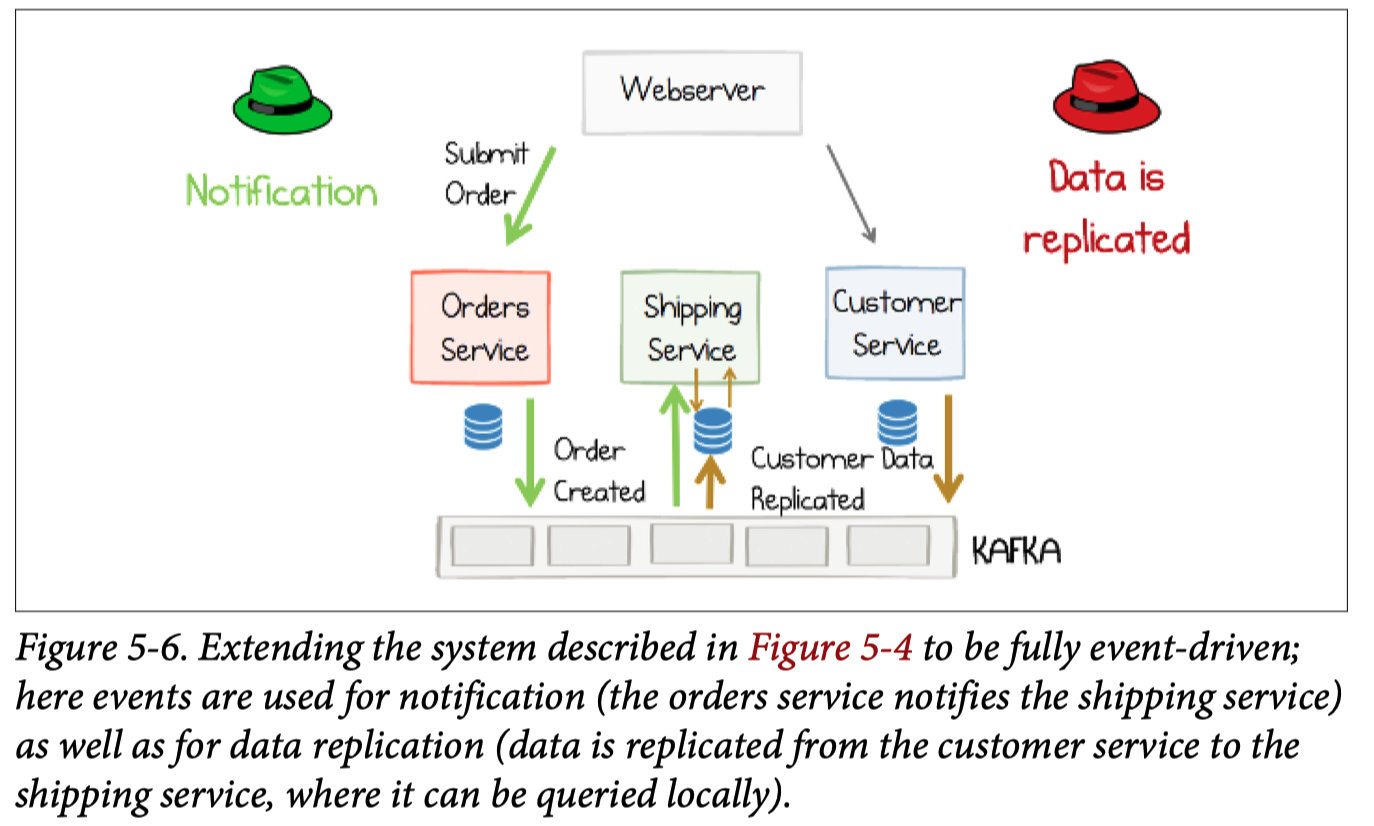
Event driven doesn’t enforce streaming processing.
Shanhe: streaming processing is good at implementing event-driven system.
Chapter 6 Processing Events with Stateful Functions
Say we have an email service that listens to an event stream of orders and then sends confirmation emails to users once they complete a purchase.
The event driven approach
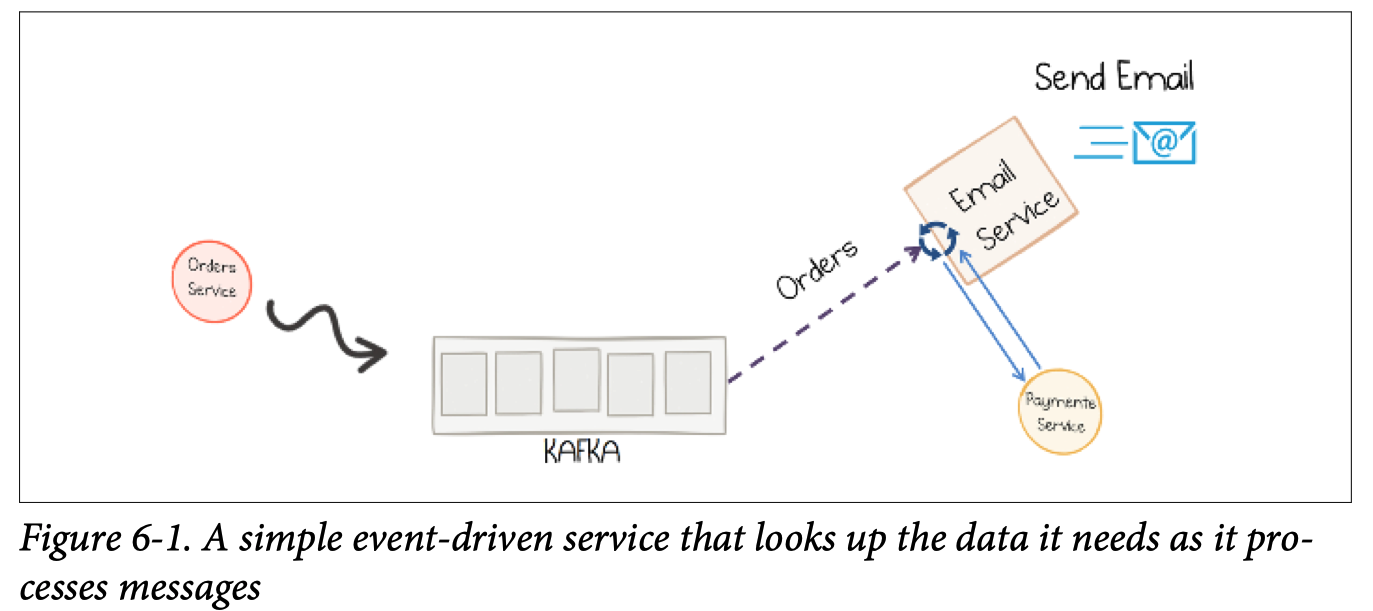
Problems
- lookup , per message, into the database or any state store.
- payment, order created at the same time, but may arrive in different order. if order arrives, and payment info is not ready yet, we have to either poll or block until we get the information.
The stateless streaming approach
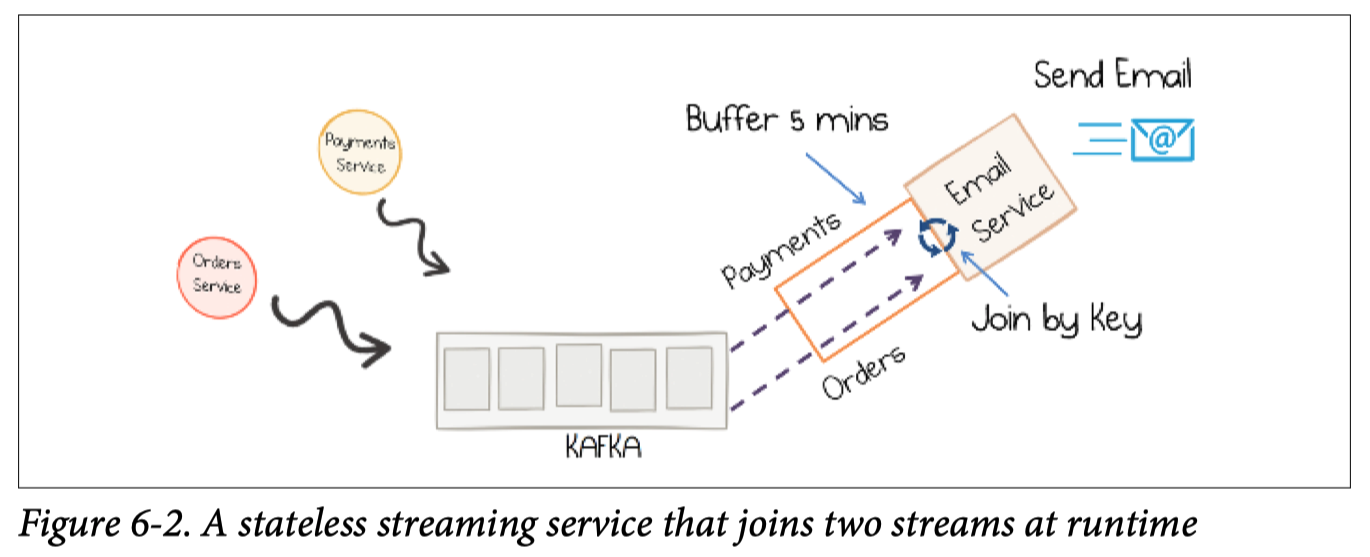
The streams (payment, order) are buffered until both events arrive, and can be joined together.
- no remote lookups
- no matter which event arrives first
Shanhe: The books says this is a sort of stateless. But I am not so sure. This clearly falls into the stateful streaming as usually we will use a state store for this purpose. It is just the state is kinda local. It really depends on the business logic of how you need to process the data.
The stateful streaming approach
What if there are more state needs to be looked up and are not in the streams. Then we fallback the previous appraoch, in the stream processor we need to do remote lookup into another service. In this case, there are futher optimization - preload the whole lookup into the email service, i.e., creating a local lookup table.
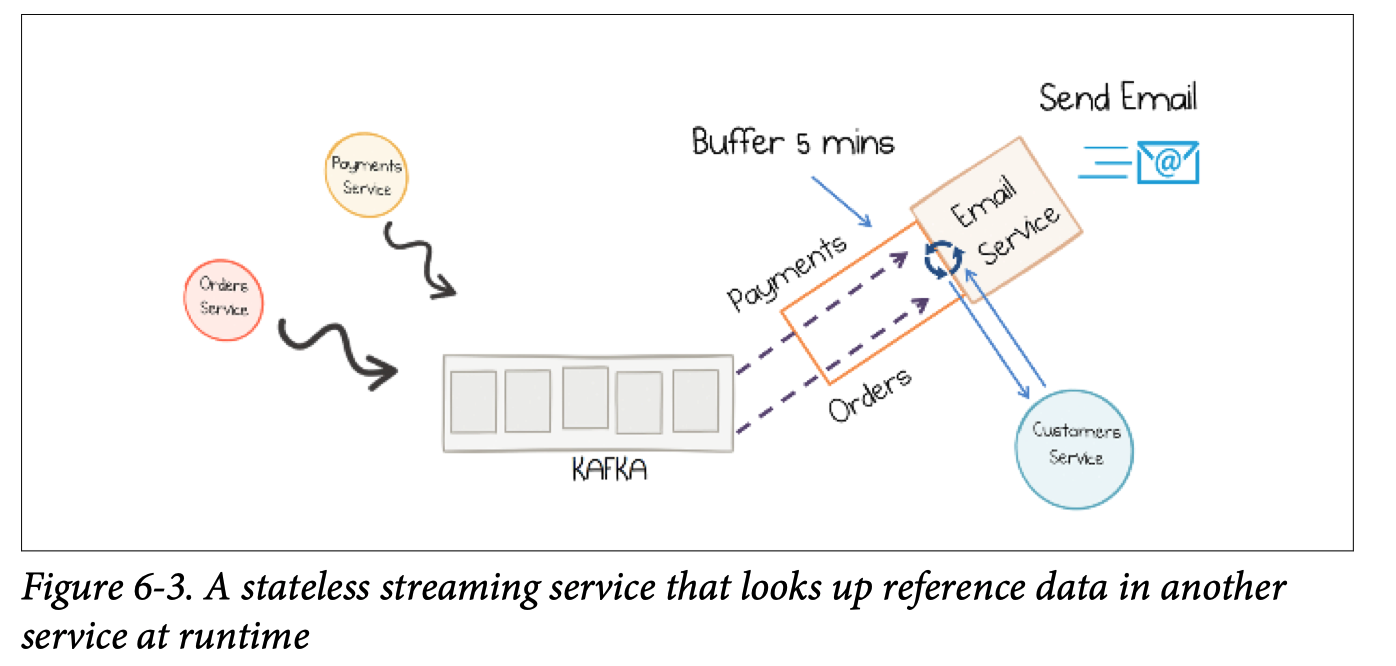
Disadvantages:
- The service is now stateful, meaning for an instance of the email service to operate it needs the relevant customer data to be present. This means, in the worst case, loading the full dataset on startup.
Advantages:
- The service is no longer dependent on the worst-case performance or liveness of the customer service
- The service can process events faster, as each operation is executed without making a network call.
- The service is free to perform more data-centric operations on the data it holds
My comment: Here comes my follow up, what if the lookup information are changging.
One solution is to poll or get notified the change and load lookup from the customer service. This basically will forfeit the previously mentioned optimiazation, and the system will depend on the worse-case perofmrance and liveness of the customer services.
Another solution is you have to bake the event of customer service into your streams as well.
Chapter 7 Event Sourcing, CQRS, and Other Stateful Patterns
Event is something that can change the state of the service.
Command is a subset of events that mainly as input to the service. So commands are events from user of the service.
What are the beneifits to store events as log?
- version control for your data. You can always replay.
- make event the source of truth
Event Sourcing
Using event to model every change to the state of an application. A good example gave by Martin Fowler is say you have an application tracking ship locations. You can either have recorded the location of every ship at any moment. Or you can only log the movement of the ship (event). As long as you have the movements of the ship, you can re-derive the location of the ship at any time.
Command Sourcing
Command sourcing is a variant of event sourcing, which applies to events that come into a service, rather than via the events it creates. In short, command sourcing is using log to record user input to the service.
Command Query Responsibility Segregation (CQRS)
For CQRS please see This It is a kind of read-write isolation.
- On the write path: User intents arrvies as command will be processed (can apply comand source) and change the application state
- On the read path: The application state can be queried.
- Write and read can be optimized independently
Due to read model is updated async, it will run slightly behind the write model. If a user performs a write, then immediately performs a read, it is possible that the entry they wrote originally has not had time to propagate, so they can’t “read their own writes.”
Materialized View
Materialized View is very close to the query side of CQRS.
A materialized view is a table that contains the results of some predefined query, with the view being updated every time any of the underlying tables change.
Or simply put, precomputed table view. In relational database, it is more like maitaining a table that can be read without any post query computation and serve to user.
Polyglot View
there is no “one-size-fits-all” approach to databases
One Write into multiple views.
Chapter 8 Sharing Data and Services Across an Organization.
Encapsulation encourages us to hide data, but data systems have little to do with encapsulation.
Service interfaces inevitably grow over time to the point where they start to look like some form of kooky, homegrown database.
We need to consider Data as a first-class citizen of the architectures we build.
- as architectures grow and systems become more data-centric, moving datasets from service to service becomes an inevitable part of how systems evolve;
- data on the outside—the data services share—becomes an important entity in its own right;
- sharing a database is not a sensible solution to data on the outside, but sharing a replayable log better balances these concerns, as it can hold datasets long-term, and it facilitates eventdriven programming, reacting to the now.
Chapter 9 Event Streams as a Shared Source of Truth
Database Inside Out with Kafka
The idea that a database has a number of core components—a commit log, a query engine, indexes, and caching—and rather than conflating these concerns inside a single black-box technology like a database does, we can split them into separate parts using stream processing tools and these parts can exist in different places, joined together by the log.
Chapter 10 Lean Data
Lean data is a simple idea: rather than collecting and curating large datasets, applications carefully select small, lean ones—just the data they need at a point in time—which are pushed from a central event store into caches, or stores they control. The resulting lightweight views are propped up by operational processes that make rederiving those views practical.
Consider using event streams as the source of truth
If message remembers, databases don’t have to. You can re-generate a databse or event-sourced view completely from the log. Why?
- when message layer is ephermeral, we have to write every message into databases, which is heavyweight as many application/services retaining copies of large proportion of the data. these copies tend to diverge and have qualitu issues.
- In stream processing, stream processor creates views (cache, state store or database). If things change, just throw the old view and create a new one by reset offset to 0.
- For devops, when tuning or tweak system that creates unrecoverbale mutations to states.
Take only the data you need, nothing more
- minimize the size of resulting views
- read-optimized
Rebuilding Event-sourced views
Drawback of lean data is if you need more data, need to go back to the log and drop the view and build from scratch.
Kafka Streams
- views are kafka topics, state store,
- views are result of transformation in JVM or KSQL
- views are rebuilt if disk is lost or removed, or stream resutl took is invoked
Databases and Caches
- need write-optimized database or cache (due to drop and re-create views)
- in-memory db/cache like Redis, MemSQL, or Hazelcast
- Memory-optimized database like Couchbase
- Database allow you to disable journaling like Mongodb
- Write/disk optimized, log-structured database like Cassandra or RocksDB
Handle the Impracticalities of Data Movement
How to speedup the rebuiling of the event-sourced views, with larger datasets.
If you need to rebuild terabyte-sized datasets in a single instance of a highly indexed, disk-resident database, this load time could well be prohibitively long.
As a yardstick, RocksDB (which Kafka Streams uses) will bulk-load ~10M 500 KB objects per minute (roughly GbE speed). Badger will do ~4M × 1K objects a minute per SSD. Postgres will bulk-load ~1M rows per minute
Because of this lead time, when releasing new software, developers typically regenerate views in advance (or in parallel), with the switch from old view to new view happening when the view is fully caught up.
Shanhe: I think there is another thing not taken in considerations: what if the views have dependencies. This will definitely increate the lead time. I have been facing this in my work and I don’t have a good solution.
Chpater 11 Consistency and Concurrency in Event-Driven Systems
Eventual Consistency
Timeliness
If two services process the same event stream, they will process them at different rates, so one might lag behind the other. If a business operation consults both services for any reason, this could lead to an inconsistency.
Shanhe: This is more like a design issue to me. Given this is determiend by business logic (e.g., one services need view from aother service). Adding serialization is the only.
Collisions
If different services make changes to the same entity in the same event stream, if that data is later coalesced—say in a database—some changes might be lost.
If we design the system to execute serially, this won’t happen, but if we allow concurrent execution it can.
The Single Writer Principle
Conflating writes into a single service makes it easier to manage consistency efficiently.
Command Topic
Uses two topics per entity,C ommand and Entity. Command topic can be written to by any process and is used only for the initiating event. The Entity topic can be written to only by the owning service: the single writer.
Single Writer Per Transition
less stringen variant of single writer principle.
Atomicity with Transaction
Kafka provides a transactions feature with two guarantees:
- Messages sent to different topics, within a transaction, will either all be written or none at all.
- Messages sent to a single topic, in a transaction, will never be subject to duplicates, even on failure.
Chpater 12 Transactions, but Not as We Know Them.
The Duplication Problem
If you make a call to a service and it’s not running for whatever reason, you retry, and eventually the call will complete. One issue with this is that retries can result in duplicate processing, and this can cause very real problems (e.g. payments).
Many systems simply push data to a database, which will automatically deduplicate based on the primary key. Such processes are naturally idempotent.
Using the Transactions API to Remove Duplicates
Exactly Once Is Both Idempotence and Atomic Commit
How kafka’s transaction works?
Snapshot Marker Mode by Chandy and Lamport.
Begin markers then commit or abort marker. To make this work, when a consumer sees a Begin marker it starts buffering internally. Messages are held up until the Commit marker arrives.
To ensure each transaction is atomic, sending the Commit markers involves the use of a transaction coordinator. The transaction coordinator is the ultimate arbiter that marks a transaction committed atomically, and maintains a transaction log to back this up (this step implements two-phase commit).
Chapter 13 Evolving Schemas and Data over Time
There are a fair few options available for schema management: Protobuf and JSON Schema are both popular, but most projects in the Kafka space use Avro. For central schema management and verification, Confluent has an open source Schema Registry that provides a central repository for Avro schemas.
Using Schemas to Manage the Evolution of Data in Time
Don’t use Java serialization or any non-evolvable format across services that change independently.
Shanhe: I recently run across protobuf over Kafka and found a few tools from Uber quite useful. They are prototool and buf.
Handling Schema Change and Breaking Backward Compatibility
What if there are breaking changes.
- Dual publish in both schema v1 and v2
- write to v2, then add a stream job to down vert v2 to v1
- write to v1, add a stream job to up convert to v2
- migrate the data in the dataset internally.
Handling Unreadable Messages
dead letter queue
Some implementers choose to create a type of dead letter queue of their own in a separate topic. If a consumer cannot read a message for whatever reason, it is placed on this error queue so processing can continue. Later the error queue can be reprocessed.
Delete Data
the simplest way to remove messages from Kafka is to simply let them expire.
Triggering Downstream Deletes
If you’re using CDC this will just work: the delete will be picked up by the source connector, propagated through Kafka, and deleted in the sinks. If you’re not using a CDC-enabled connector, you’ll need some custom mechanism for managing deletes.