[VLDB'13] Millwheel: Fault-tolerant Stream Processing at Internet Scale
@article{akidau2013millwheel,
title={MillWheel: fault-tolerant stream processing at internet scale},
author={Akidau, Tyler and Balikov, Alex and Bekiro{\u{g}}lu, Kaya and Chernyak, Slava and Haberman, Josh and Lax, Reuven and McVeety, Sam and Mills, Daniel and Nordstrom, Paul and Whittle, Sam},
journal={Proceedings of the VLDB Endowment},
volume={6},
number={11},
pages={1033--1044},
year={2013},
publisher={VLDB Endowment}
}
This is a paper published by Google at 2013, talking about the streaming processing programming model at Google. It has huge impact on other streaming processing systems, like, spark streaming, or streaming processing libraries such as Kafka Streams, and also lead to Google Cloud Product DataFlow, and the streaming processing library Apache Beam that targets at providing unified programming interfaces for both Batch and streaming processings.
Streaming processing can provide low lantency results.
Streaming systems at Google require fault toleranace, persistent, state, and scalability.
MillWheel is a programming model, tailored specifically to streaming, low-latency systems.
- write application logics by defining topology (in individual nodes in a directed compute graph)
- records are delivered along the edges of the graph
- assuming any node/edge can fail at any time, that calls for fault tolerance
- idempotent api, exactly once record dilivery
- checkpoint the progress at fine granularity, no need to buffering data for long period between checkpoints
Motivation and Requirements
The paper uses Google’s Zeitgest pipeline, which serves the hot treand topics, as an example to get idea of the motivation and requiremetns for MillWheel.
THe system is implemented in an approach that
- bucket records into one-second interval
- compare the actual and predicted results (model deviation)
- if the quantities are consistenly different in a non-trival number of buckets, the model changed, the query is spiking or dipping.
- update the model, when there is model deviation
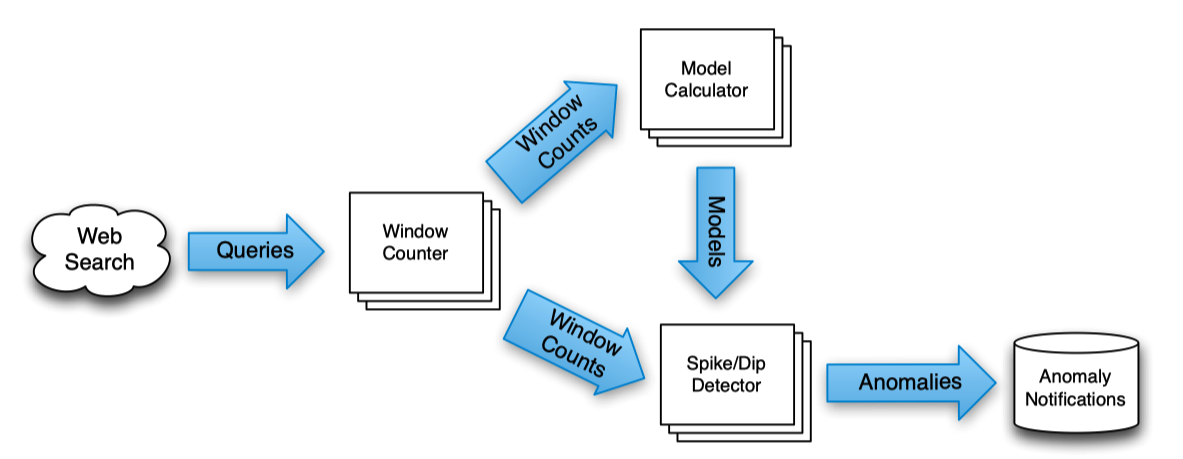
Persistent Storage
Storage requires both short- and long-term. Spike data are transient, that only last a few second. But the model can be used and gets constantly updates for months.
Low Watermarks
Watermark concept is very import for understanding stream processing. It is watermark in term of record time. A Low watermark means all events happen before this timestamps are finalized. If you compare low watermark to the current timestamp. It kinds of defines a duration for how long you will wait for late events. Watermark means a final answer, and discard any answer after the final answer.
A low watermark for each processing stage, which indicates that all data up to a given timestamp has been received. The low watermark tracks all pending events in the distributed system.
This can help for differentiating 1) queries are delayed, 2) no quries.
Duplicate Prevention (Exact once processing)
Requirements:
- Data should be available to consumer as soong as it is published
- persistent state abstractions should be available to user code (user can do stateful streaming)
- out-of-order data should be handled gracefully
- system can compute a monotonically increasing low watermark of data timestamps
- lantecy stays constant as system scales
- exactly-once deliver of records
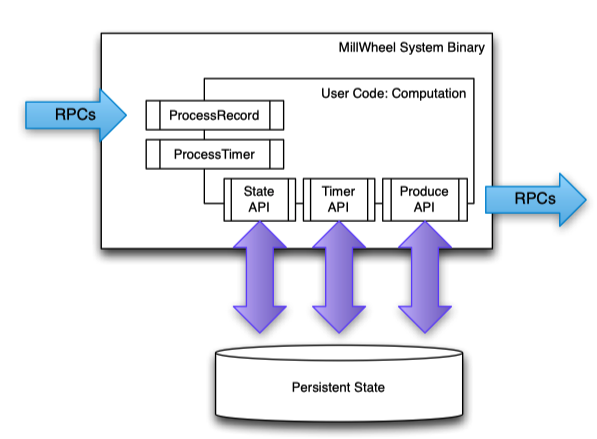
System Overview
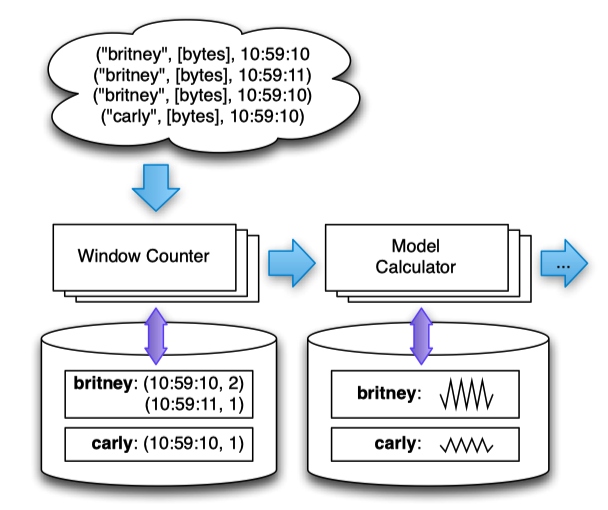
At a high level, MillWheel is a graph of user-defined transformations on input data that produces output data. These transformations are called computations.
inputs and outputs in MillWheel are represented by (key, value, timestamp) triples. While the key is a metadata field with semantic meaning in the system, the value can be an arbitrary byte string, corresponding to the entire record.
All internal updates within the MillWheel framework resulting from record processing are atomically checkpointed per-key and records are delivered exactly once. This guarantee does not extend to external systems
Core Concept
Computations
Single Node Definition
1// Code sample from the paper
2computation SpikeDetector {
3 input_streams {
4 stream model_updates {
5 key_extractor = ’SearchQuery’
6 }
7 stream window_counts {
8 key_extractor = ’SearchQuery’
9 }
10 }
11 output_streams {
12 stream anomalies {
13 record_format = ’AnomalyMessage’
14 }
15 }
16}
Keys
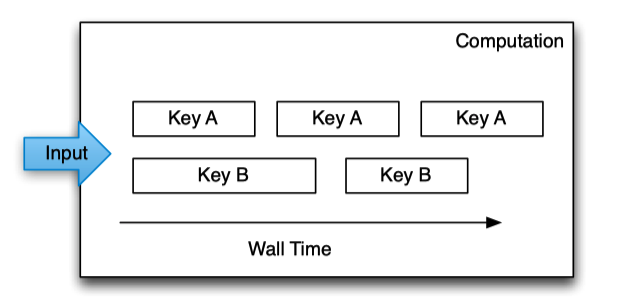
Keys are the primary abstraction for aggregation and comparison between different records in MillWheel.
Computation code is run in the context of a specific key and is only granted access to state for that specific key.
Per-key processing is serialized over time only one record can be procesed for a given key at once. Multiple keys can run in parallel.
The consumer specifies a key extraction function, which assigns a key to the record.
Multiple computations can extract different keys from the same stream.
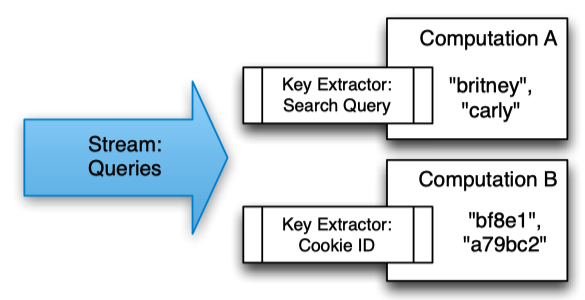
Streams
Streams are the delivery mechanism between different computations in MillWheel. Streams are uniquely identified by their names, with no other qualifications – any computation can subscribe to any stream, and can produce records (productions) to any stream.
Persistent State
In its most basic form, persistent state in MillWheel is an opaque byte string that is managed on a per-key basis.
The user provides serialization/deserialization methods.
Low Watermark
The definition low watermark of A to be
min(oldest work of A, low watermakr of C: C outputs to A)
oldest work of A is a timestamp corresponding to the oldest unfinished record in A.
If there is no input streams, the low watermakr = oldest work values.
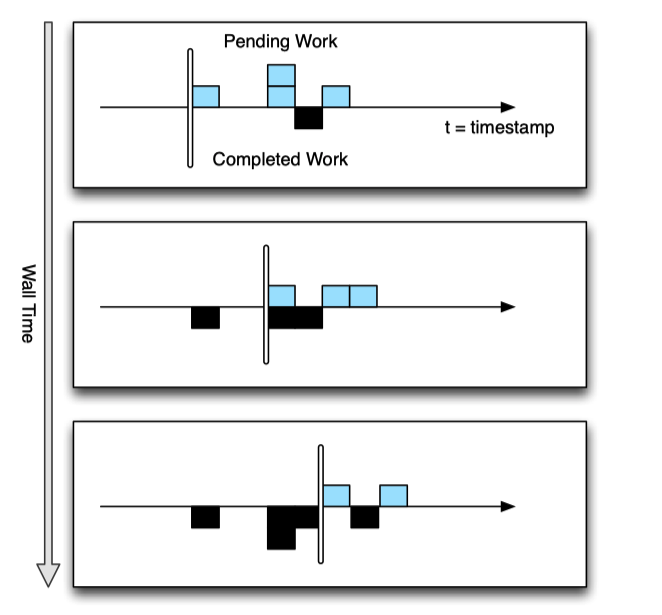
The low watermark advances as reacords are processed by the system.
Data are not necessarily processed in-order, but the low watermark give you the idea of what are still pending in the system.
Timers
Shanhe: If you are faimilar with Kafka Streams, this is the punctuation.
Timers are hooks trigger at a speicial wall time or low watermark.
When to use wall time, or low watermark time, is dependent on the applications.
The timers are journaled in persistent state, and can survive process restarts and machine failures.
API
1class Computation {
2
3 // Hooks called by the system.
4 void ProcessRecord(Record data);
5 void ProcessTimer(Timer timer);
6
7 // Accessors for other abstractions.
8 void SetTimer(string tag, int64 time);
9 void ProduceRecord(Record data, string stream);
10 StateType MutablePersistentState();
11};
Computation API
1// Code sample from the paper
2
3// Upon receipt of a record, update the running
4// total for its timestamp bucket, and set a
5// timer to fire when we have received all
6// of the data for that bucket.
7
8void Windower::ProcessRecord(Record input) {
9
10 WindowState state(MutablePersistentState());
11
12 state.UpdateBucketCount(input.timestamp());
13
14 string id = WindowID(input.timestamp())
15
16 SetTimer(id, WindowBoundary(input.timestamp()));
17}
18
19// Once we have all of the data for a given
20// window, produce the window.
21
22void Windower::ProcessTimer(Timer timer) {
23
24 Record record =
25
26 WindowCount(timer.tag(), MutablePersistentState());
27
28 record.SetTimestamp(timer.timestamp());
29
30 // DipDetector subscribes to this stream.
31
32 ProduceRecord(record, "windows");
33}
34
35// Given a bucket count, compare it to the
36// expected traffic, and emit a Dip event
37// if we have high enough confidence.
38
39void DipDetector::ProcessRecord(Record input) {
40 DipState state(MutablePersistentState());
41 int prediction = state.GetPrediction(input.timestamp());
42 int actual = GetBucketCount(input.data());
43 state.UpdateConfidence(prediction, actual);
44 if (state.confidence() > kConfidenceThreshold) {
45 Record record = Dip(key(), state.confidence());
46 record.SetTimestamp(input.timestamp());
47 ProduceRecord(record, "dip-stream");
48 }
49
50}
Injector and Low Watermark API
Injector bring external data into the system. It decides the init (seeds) low watermark for the rest of the pipeline. Injector can be distributed, then the low watermark needs to be aggregated.
If the injector violates the lower watermark semantics, and sends a later record, user application code can choose how to handle it.
For example, if the injector is loading files, it can use the creation time of the file.
1// Upon finishing a file or receiving a new
2// one, we update the low watermark to be the // minimum creation time.
3
4void OnFileEvent() {
5 int64 watermark = kint64max;
6 for (file : files) {
7 if (!file.AtEOF())
8 watermark = min(watermark, file.GetCreationTime());
9 }
10 if (watermark != kint64max)
11 UpdateInjectorWatermark(watermark);
12
13}
Fault Tolerance
Exactly Once
Upon receiing one record for a computation,
- record is checked against deduplicate data from previous record, if duplicate then discard
- run user code for the input record, it is possible resulting in pending changes to timer, state and productions.
- pending changes are commited to the backing store
- sender are ACKed
- pending downstream productions are sent
In order for at-least-once (prerequisite for exactly-once), deliveries are retried until they are ACKed. Retry can happen when there is network failure or machine failure. So we could have duplicate records (e.g., reciever crashed before sending ACK, but the record is persisted, producer didnt get ACk, will retry which results in duplicate records).
The system assigns unique IDs to all records at production time. We identify duplicate records by including this unique ID for the record in the same atomic write as the state modification.
This is done by a bloom filter in memory. In case of filter misss, will read the backing store to determine if it is duplicate.
Strong Productions
Strong productions means checkpointing before record production.
To use aggreates counts as an example.
Without checkpointing, the computation could produce a a window count downstream, but crashed before saving this state. When the comptuation came back, it can receive a another record, and produce the same aggregate, creating a record that was bit-wise distinct from its predecessor but corresponded to the same logical window.
According to the paper, this needs complex logics to do it at downstream consumer. With strong productions, the user application logic can remain idempotent.
The implementation is via a storage system like Bigtable, making checkpoints mimic the behaivor of a log. When a process restarts, the checkpoints are scanned into memory and replayed. Checkpoint data is deleted once these productions are successful.
Shanhe: Kafka Streams has the similar design, that use a internal kafka topics to store the state change events, and processor and its state can recover from it.
Weak Productions and Idempotency
Depending on the semantic needs of an application, strong productions and/or exactly-once can be disabled by the user at their discretion.
Weak production means braodcasting records before persisting state.
Compared with Strong productions, once you persist the states, you dont have to worry anyting. Now, the up stream waits for the ACKs from the downstreams. Give the machine can fail, this can increase the end-to-end latency for traggler.
We ameliorate this by checkpointing a small percentage of straggler pending productions, allowing those stages to ACK their senders. By selectively checkpointing in this way, we can both improve end-to-end latency and reduce overall resource consumption.
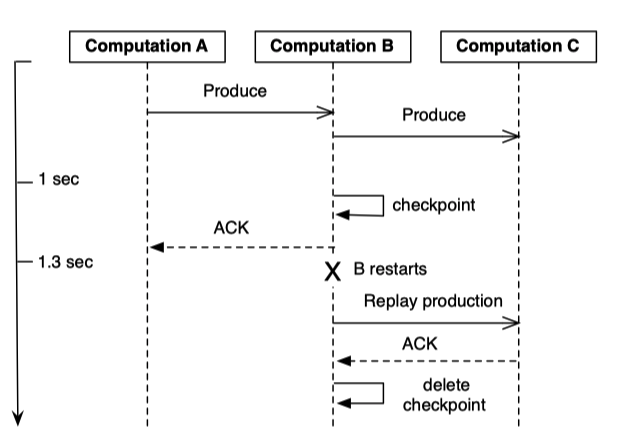
Computation A produces to Computation B, which immediately produces to Computation C. However, Computation C is slow to ACK, so Computation B checkpoints the production after a 1-second delay. Thus, Computation B can ACK the delivery from Computation A, allowing A to free any resources associated with the production. Even when Computation B subsequently restarts, it is able to recover the record from the checkpoint and retry delivery to Computation C, with no data loss
State Manipulation
hard state (in bbacking store) and soft state (in memory)
- the sytem does not lose data
- updates to satte obey exactly-once semantics.
- persisted data must be consitent
- low watermarks must reflect all pending state in ssytem
- timers must fire in order for a given key.
To avoid incosistencies in persisted state, per-key updates are wrapped into a single atomic operations.
As work may shift between machines (due to load balancing, failures, or other reasons) a major threat to our data consistency is the possibility of zombie writers and network remnants issuing stale writes to our backing store
attach sequencer token to each write, the backstore will check before commit the write.
Make use of single writer for consistency of soft state, lead to a always consistent soft state.
Our use of always-consistent soft state allows us to minimize the number of occasions when we must scan these checkpoints to specific cases – machine failures or load-balancing events. When we do perform scans, these can often be asynchronous, allowing the computation to continue processing input records while the scan progresses.
Transaction cannot guarantee. For example if a remnant write from another process could alter the persisted timer state after said cache was built, the cache would be inconsistent. Same situation can occur with the checkpointed production.
Implementations
Architecture
Hosts communicate via RPC.
Load balancing is handled by a replicated master, divides each computation into a set of owned lexicographic key intervals, then keys are assigned to a set of machines. Intervals can be moved, splitted, merged. Each interval is assigned to a unique sequencer.
Persistent state, it relies on Bigtable/Spanner. Imters, pending productions, and persistent state for a given key are all stored on the same row.
Implementation Details of Low Watermarks
A globally available sub-system. It is implemented a a central authoroity. which tracks all low watermark values in the system and journals them to persistent state, preventing the reporting of erroneous values in cases of process failure.
Since processes are assigned work based on key intervals, low watermark updates are also bucketed into key intervals, and sent to the central authority. The authority then broadcasts low watermark values for all computations in the system
Interested consumer computations subscribe to low watermark values for each of their sender computations, and thus compute the low watermark of their input as the minimum over these values.
To maintain consistency at the central authority, we attach sequencers to all low watermark updates.