DAPR - 为云和边缘设计的分布式程序运行环境 (1) 基本概念
本篇内容参考主要来自官方文档
什么是 DAPR
一个事件驱动,便携的, 在云和边缘上构建微服务的运行环境(An event-driven, portable runtime for building microservices on cloud and edge).
DAPR 是一个分布式应用运行环境 (distributed application runtime)
- Dapr 利用 side-car(容器/进程) 负责所有的计算节点的通信。
- 自带状态管理(state management), in-memory或者persisted
- 可靠的消息系统,至少一次递送保障
- HTTP/gRPC接口提供 event tirggers/bindings
- 可以host在k8s,也可以在local,甚至iot设备,容器等。
在早期的时候,Dapr还有提到serverless,不过按照目前的趋势,serverless已经从文档中被去掉,说明微软对dapr还有更大的期待,不想用一个serverless来限制其可能性。
Building Blocks
Dapr除了运行环境,还提供了一系列的building blocks。这使得dapr拥有一个丰富的工具箱,可以轻松搭建一些应用。
Serivce-to-service Invocation
通过一个统一的endpoint /v1.0/invoke, 一个服务可以轻易的调用另外一个服务。
Dapr提供HTTP和gRPC两种方式。 这个endpoint既承担了反向代理,也自带服务发现。
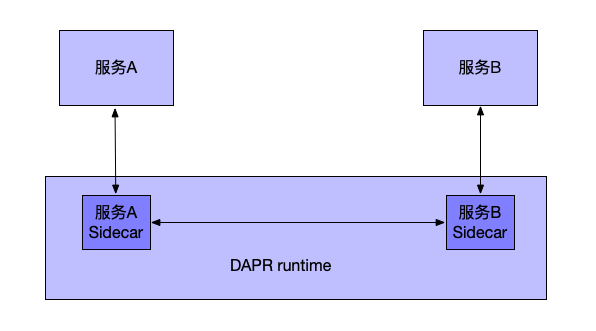
Middleware
Dapr还支持用户自定义request process中间件。可以用来提供一些常见的功能:鉴权,加密,消息预处理等。
State Management
Let state be somebody else’s problem 很多时候, 我们在工程中面临的挑战都来自state: state维持在哪里?存在哪里?如何存?如何保持正确性,当错误发生的时候如何从state中recover等等。
DAPR通过统一的接口,允许你访问各种state store,目前支持的有
| Name | CRUD | Transactional |
|---|---|---|
| Aerospike | Yes | No |
| Cassandra | Yes | No |
| Cloudstate | Yes | No |
| Couchbase | Yes | No |
| etcd | Yes | No |
| Hashicorp Consul | Yes | No |
| Hazelcast | Yes | No |
| Memcached | Yes | No |
| MongoDB | Yes | Yes |
| PostgreSQL | Yes | Yes |
| Redis | Yes | Yes |
| Zookeeper | Yes | No |
| Azure CosmosDB | Yes | Yes |
| Azure SQL Server | Yes | Yes |
| Azure Table Storage | Yes | No |
| Azure Blob Storage | Yes | No |
| Google Cloud Firestore | Yes | No |
State Concurrency
对于state的读写,Dapr支持乐观并发控制,即假设多数用户的并发事务不会冲突。 DPAR利用Etag来实现乐观并发控制。 写操作只有当Etag和state中的Etag匹配的时候才会成功,反之则需要回滚并重试。 Dapr自带支持定义retry policy。
如果有没有Etag,那么Dapr相当于last-wrtie-win。
并不是所有的underlying state store都支持etag,如果不支持,dapr需要state store 实现中去模拟这个etag,因为dpar的state store其实就是 underlying state store的客户端,所以应该比较容易实现。
Consistency
对于一致性,dapr支持强一致性和最终一致性(默认)。
对于强一致性,dapr会等所有的replica(或者设定的quorums)确认了写请求之后,才会返回。对于最终一致性,则只要写请求并state store接受之后,就会返回。
Retry Policy
Dapr允许我们对任意一个写请求,设定一个retry policy。 在重试策略中,可以定义retryInterval, retryPattern(线性或者指数退避), retryThreshold.
Bulk Operations
Dapr支持两种
- bulk,可以理解为a batch of requests of same type, Dapr还是会依次提交给底下的state store,所以bulk不支持事务
- multi,group request of different types,这是被当作一个原子性的事务操作。
Publish and Subscribe
DAPR还支持pubsub,来帮助服务之间通信。 DAPR提供了at-least-once guarantee。
- App ID: 每一个应用需要一个id,当同一个application id的instances都subscribe同一个话题的时候,dapr保证了只有一个instance会收到。
- Dapr对于event的封装是用的 Cloud Event 1.0 Spec
Resource Binding
Binding的主要目的是使得Dapr中的服务,可以被外部系统的event触发,或者可以通过事件去调用外部的系统。因此有input binding和output binding两种。 在事件驱动系统中,binding很关键,我的理解是它们相当于sink/source/connector这样的抽象。
- 只需要关注业务逻辑,不用实现如何具体和某一个系统互动
- 消除了和消息队列连接拉取数据的复杂性
- 可以在runtime的时候修改binding
- 增强了可移植性,因为binding提供了一层抽象,所以业务逻辑和input/output的具体实现是解耦的(decoupled)
Actor
Dapr在并发和时间处理上使用的是Actor模型。
Actor Model
- 一个actor是一个可以做计算的实体
- actor接收消息
- actor可以给其他actor发消息
- actor可以创建新的actor
- 对于并发的消息,并没有order保障
这里是Akka对于Actor Model的介绍
Virtual Actor Abstraction
至于实现,dapr使用的是virtual actor。 详情可以去读这一篇文章
- Dapr actors 是virtual actor,其生命周期不等同于其在内存中存在的周期。 virtual actor不需要显式的创建和销毁。
- Dapr runtime会在actor第一次接受request的时候自动的激活actor
- Dapr runtime中有一个garbage-collect会回收内存中的对象。并维护actor的信息,知道一个actor是否需要在还需要激活。
Distribution and failover
Dapr runtime需要决定actor实例应该如何分布在整个cluster中。 一旦cluster中一个节点fail了,Dapr会自动将上面的actor迁移到还健在的host上。
Actor Placement Service,有点像是一个sharding service。当一个服务新实例被创建时,Dapr就会根据这个服务能创建的actor type,注册到runtime,而Placement service则会计算这个actortype的partitioning。这个paritioning信息存在每一个dapr runtime,并且会动态的更新。
Actor Concurrency
对于actor内的方法调用,Dapr使用的是 turn-based access model.
No more than one thread can be active inside an actor object’s code at any time
这种设置简化了系统并发,同时也需要在设计的时候有一些额外的考虑
- 对于data access,不需要做同步,因为是single thread write。。
- 一个actor只能每次处理一个request,如果一个actor被设计成要处理concurrent requests,那么就会成为bottleneck
- 当有环存在的时候,actor也会死锁,所以会有一个Dapr会自动time out超时的actor call
Observability
感觉这一部分就是很标准化,modern app基本都需要,就不再花更多的篇幅。
- Metric: OpenTelemetry, Prometheus and Grafana
- Logs: Fluentd
- Distributed tracing: Zipkin
Secrets
Dapr提供sercrets API这样一层封装来帮助用户管理secrets
目前支持的secret store有
- Kubernetes
- Hashicorp Vault
- Azure KeyVault
- AWS Secret manager
- GCP Cloud KMS
- GCP Secret Manager
Installation (MacOs)
利用Homebrew安装的Dapr CLI
brew install dapr/tap/dapr-cli
➜ dapr
__
____/ /___ _____ _____
/ __ / __ '/ __ \/ ___/
/ /_/ / /_/ / /_/ / /
\__,_/\__,_/ .___/_/
/_/
======================================================
A serverless runtime for hyperscale, distributed systems
Usage:
dapr [command]
Available Commands:
completion Generates shell completion scripts
components List all Dapr components
configurations List all Dapr configurations
dashboard Start Dapr dashboard
help Help about any command
init Setup dapr in Kubernetes or Standalone modes
invoke Invokes a Dapr app with an optional payload (deprecated, use invokePost)
invokeGet Issue HTTP GET to Dapr app
invokePost Issue HTTP POST to Dapr app with an optional payload
list List all Dapr instances
logs Gets Dapr sidecar logs for an app in Kubernetes
mtls Check if mTLS is enabled in a Kubernetes cluster
publish Publish an event to multiple consumers
run Launches Dapr and (optionally) your app side by side
status Shows the Dapr system services (control plane) health status.
stop Stops multiple running Dapr instances and their associated apps
uninstall Removes a Dapr installation
Flags:
-h, --help help for dapr
--version version for dapr
Use "dapr [command] --help" for more information about a command.
subcommand is required
目前Dapr的version是0.9.0
1➜ dapr --version
2CLI version: 0.9.0
3Runtime version: 0.9.0
安装Docker或者Kubernetes
1dapr init
DPAR在local模式下,自己会作为一个进程,但同时也会启动一些container实例
1➜ docker ps
2CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3223ec265e5dc daprio/dapr "./placement" 2 hours ago Up 2 hours 0.0.0.0:50005->50005/tcp dapr_placement
468d814c373ab redis "docker-entrypoint.s…" 2 hours ago Up 2 hours 0.0.0.0:6379->6379/tcp dapr_redis
5a24b2f6ce01a openzipkin/zipkin "/busybox/sh run.sh" 2 hours ago Up 2 hours 9410/tcp, 0.0.0.0:9411->9411/tcp dapr_zipkin
Hello World 例子
hello word 是一个简单的webapp
node js的后端。 提供了一个 get order,create new order, delete order的api。
http://localhost:${daprPort}/v1.0/state/${stateStoreName}
State是存放在redis中。默认Dapr会在container起一个redis实例。
这个是在用户目录下config的
1~
2➜ tree .dapr
3.dapr
4├── components
5│ ├── pubsub.yaml
6│ ├── statestore.yaml
7│ └── zipkin.yaml
8├── config.yaml
9└── daprd
pubsub 还有 statestore 默认实现都是redis
1➜ cat .dapr/components/statestore.yaml
2apiVersion: dapr.io/v1alpha1
3kind: Component
4metadata:
5 name: statestore
6spec:
7 type: state.redis
8 metadata:
9 - name: redisHost
10 value: localhost:6379
11 - name: redisPassword
12 value: ""
13 - name: actorStateStore
14 value: "true"
1➜ cat .dapr/components/pubsub.yaml
2apiVersion: dapr.io/v1alpha1
3kind: Component
4metadata:
5 name: pubsub
6spec:
7 type: pubsub.redis
8 metadata:
9 - name: redisHost
10 value: localhost:6379
11 - name: redisPassword
12 value: ""
client是一个简单的py script。
Run the nodejs app
先安装npm依赖
1npm install
跑这个nodejs app 我们会使用dapr run
1➜ dapr run -h
2Runs Dapr's sidecar and (optionally) an application.
3
4Run a Java application:
5 dapr run --app-id myapp -- java -jar myapp.jar
6Run a NodeJs application that listens to port 3000:
7 dapr run --app-id myapp --app-port 3000 -- node myapp.js
8Run a Python application:
9 dapr run --app-id myapp -- python myapp.py
10Run sidecar only:
11 dapr run --app-id myapp
12
13Usage:
14 dapr run [flags]
15
16Flags:
17 --app-id string an id for your application, used for service discovery
18 --app-port int the port your application is listening on (default -1)
19 --components-path string Path for components directory. Default is $HOME/.dapr/components or %USERPROFILE%\.dapr\components (default "/Users/yshanhe/.dapr/components")
20 --config string Dapr configuration file. Default is $HOME/.dapr/config.yaml or %USERPROFILE%\.dapr\config.yaml (default "/Users/yshanhe/.dapr/config.yaml")
21 --enable-profiling Enable pprof profiling via an HTTP endpoint
22 --grpc-port int the gRPC port for Dapr to listen on (default -1)
23 -h, --help help for run
24 --image string the image to build the code in. input is repository/image
25 --log-level string Sets the log verbosity. Valid values are: debug, info, warn, error, fatal, or panic. Default is info (default "info")
26 --max-concurrency int controls the concurrency level of the app. Default is unlimited (default -1)
27 --placement-host string the host on which the placement service resides (default "localhost")
28 -p, --port int the HTTP port for Dapr to listen on (default -1)
29 --profile-port int the port for the profile server to listen on (default -1)
30 --protocol string tells Dapr to use HTTP or gRPC to talk to the app. Default is http (default "http")
31
1dapr run --app-id nodeapp --app-port 3000 --port 3500 -- node app.js
命令行会打印一些log,其中应该会看到下列几行logs 说明app已经成功的跑了起来。
== APP == Node App listening on port 3000!
ℹ️ Updating metadata for app command: node app.js
✅ You're up and running! Both Dapr and your app logs will appear here.
mutate the state
接下来我们来调用刚才的app, 因为通信的方式是http rest 所以有很多种方法可以call我们的服务
1dapr invoke --app-id nodeapp --method neworder --payload '{"data": { "orderId": "41" } }'
2
3✅ App invoked successfully
1ℹ️ Updating metadata for app command: node app.js
2✅ You're up and running! Both Dapr and your app logs will appear here.
3
4== APP == Got a new order! Order ID: 41
5
6== APP == Successfully persisted state.
当然你还可以用curl或者postman,都没有问题。
check state store
首先我们用dapr的state api来check state
1➜ curl -XGET http://localhost:3500/v1.0/invoke/nodeapp/method/order
2{"orderId":"41"}%
我们还可以起一个redis-cli (68d814c373ab 是 redis container instance id)
1➜ docker exec -it 68d814c373ab redis-cli -h localhost
2localhost:6379> HGETALL "nodeapp||order"
31) "data"
42) "{\"orderId\":\"41\"}"
53) "version"
64) "1"
run python app to call nodejs app
例子中的python script就是一个rest client不停的call nodejs app的api去创建orders
Stop apps
1➜ dapr list
2 APP ID HTTP PORT GRPC PORT APP PORT COMMAND AGE CREATED PID
3 pythonapp 49484 49485 0 python3 app.py 5m 2020-08-03 21:02.45 58874
4 nodeapp 3500 65292 3000 node app.js 37m 2020-08-03 20:30.21 47002
1samples/1.hello-world on master is 📦 v1.0.0 via ⬢ v14.5.0
2➜ dapr stop --app-id nodeapp
3✅ app stopped successfully: nodeapp
4
5samples/1.hello-world on master is 📦 v1.0.0 via ⬢ v14.5.0
6➜ dapr stop --app-id pythonapp
7✅ app stopped successfully: pythonapp
在app跑的terminal中你会收到如下提示
ℹ️
terminated signal received: shutting down
✅ Exited Dapr successfully
✅ Exited App successfully
个人感受
我觉得DAPR做到了易用,从简单的安装一个CLI开始,就可以快速的deploy app。Cli使用的感觉很像一些serverless framework的cli,熟悉其他serverless cli的人也不会觉得很陌生。
什么样的服务最适合利用DAPR? 因为现在我只体验了dapr跑在local,下一次将会看看dapr跑在k8s会如何。Dapr提供的这些build block和统一的抽象出来的api,可能会很适合一部分应用,比如web app。不知道能否满足其他的workload的需求:比如大数据处理,机器学习这样的应用,通常对state store的会有特殊的要求,或者需要message queue提供exactly once delivery。
至于为边缘计算设计的宣传点,我可能还需要进一步的了解。虽然目前大家的共识就是如果把应用放上k8s,就可以在任何有k8s的地方跑,包括edge结点。 但是这里少了一些关于edge特点的思考,毕竟cloud和edge还是有很多不同的地方和不同的限制,因此能够形成不同的问题因而需要不同的解决方案。比如我个人比较关注的computation offloading,当你在一个local regin有能力不同的edge node的时候,如何跨edge node来做computation offloading,以及如何trade off 是offload到nearby edge还是cloud。
